2019-10-31 11:17


扫码打开虎嗅APP

本文来自公众号:机器之心(ID:almosthuman2014),原标题为《DeepMind星际争霸AI登上Nature,超越99.8%活跃玩家,玩转三大种族》,题图来自:视觉中国。
今天,DeepMind 有关 AlphaStar 的论文发表在了最新一期《Nature》杂志上,这是人工智能算法 AlphaStar 的最新研究进展,展示了 AI 在“没有任何游戏限制的情况下”已经达到星际争霸 2 人类对战天梯的顶级水平,在 Battle.net 上的排名已超越 99.8%的活跃玩家,相关的录像资料也已放出。
虽然还是打不过世界第一人类选手 Serral,但 AlphaStar 已经登上了 Nature。在 DeepMind 的最新博客中,研究者们对于这一 AI 算法的学习能力进行了详细介绍。
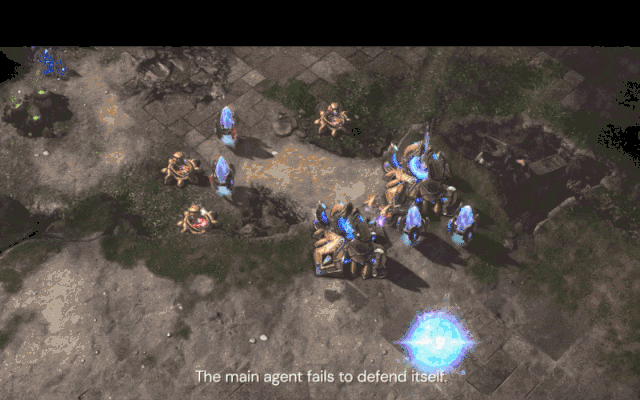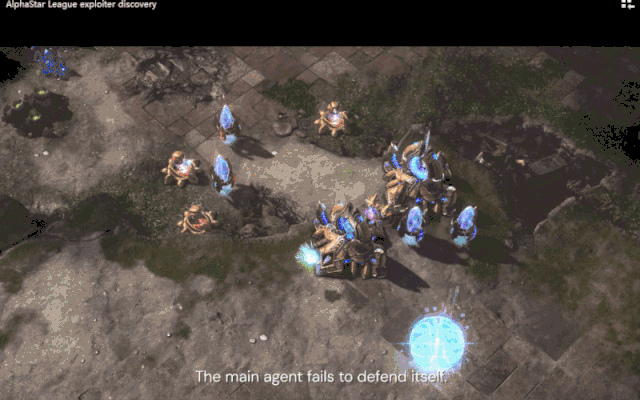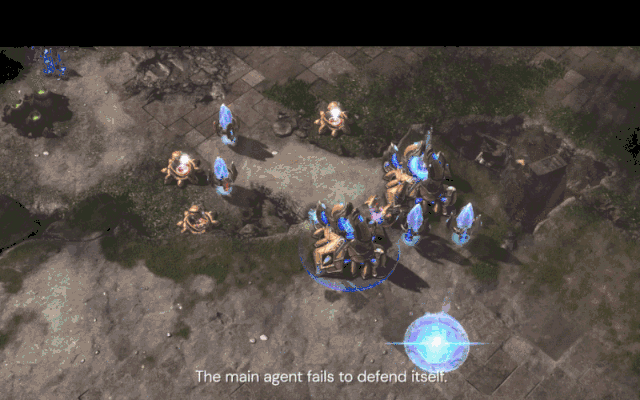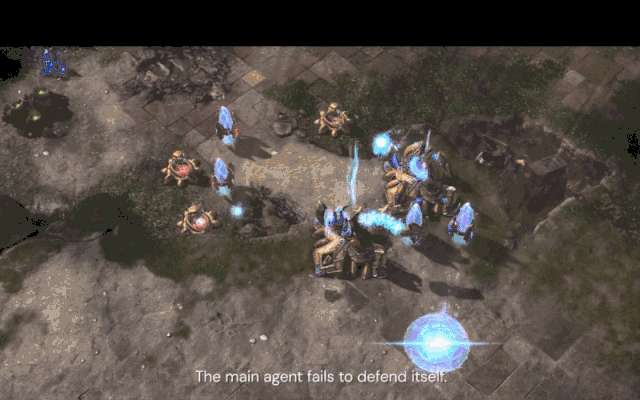
在游戏中,压榨(Exploiter)智能体(红色)发现了一种“Tower Rush”策略,从而打败了核心智能体(蓝色)。

随着训练的进行,新的核心智能体(绿色)已经学会拖农民和其他单位来对抗压榨智能体(红色)的“Tower Rush”。
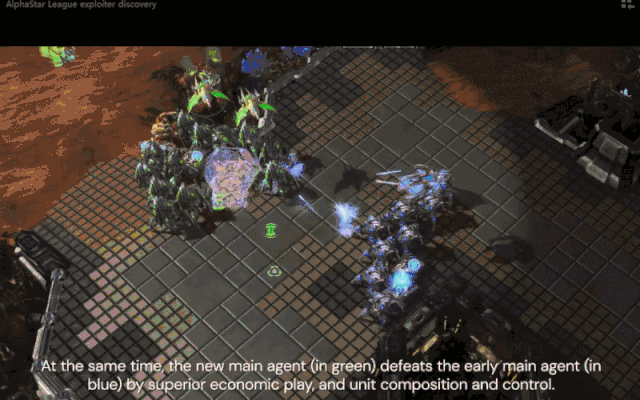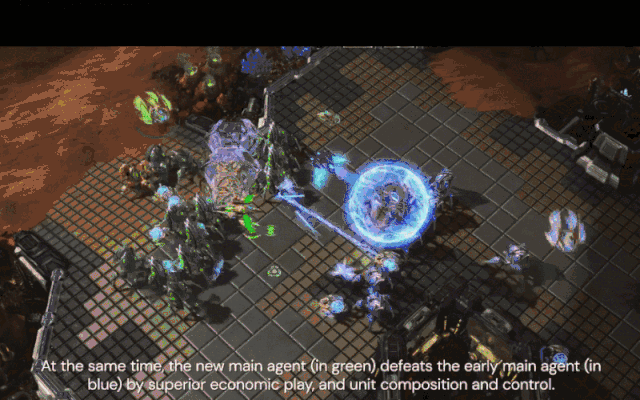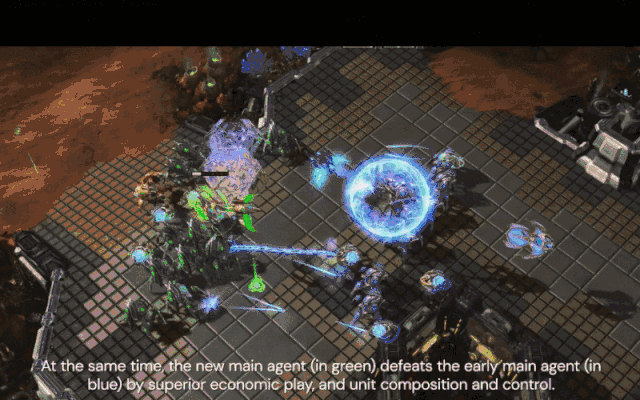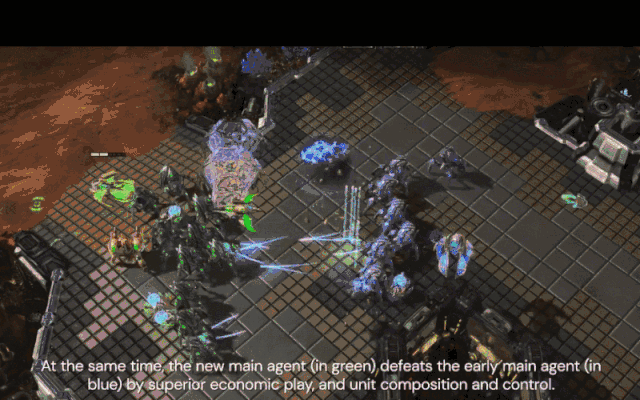
与此同时,新的核心智能体(绿色)通过优势经济、单位配合和控制击败了早期核心智能体(蓝色)。
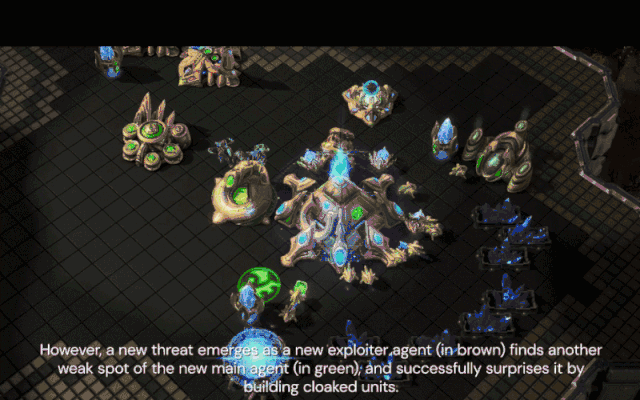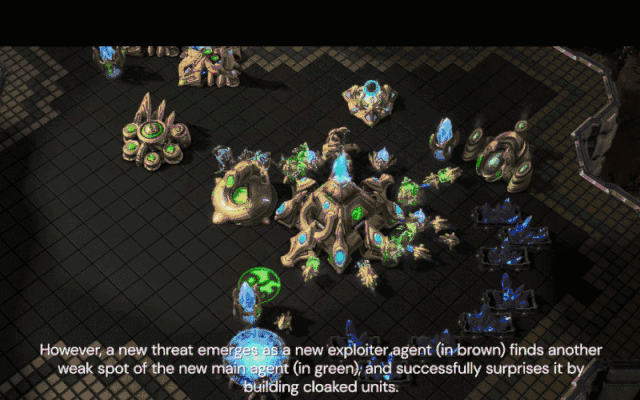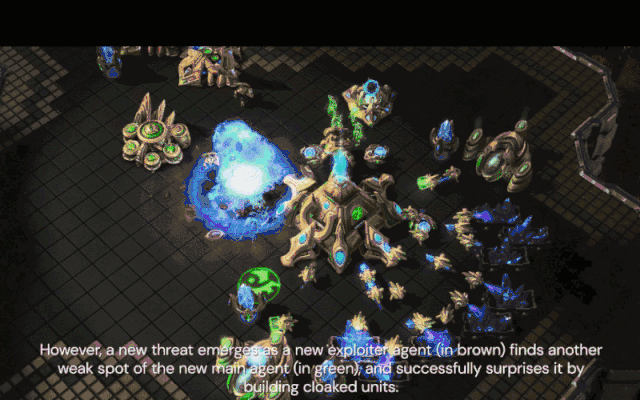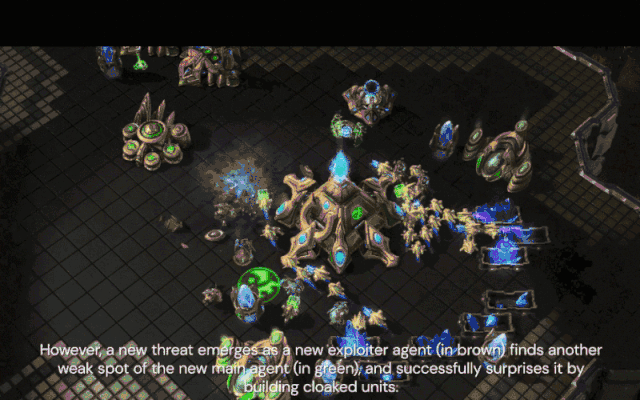
新的压榨智能体(棕色)发现了新核心智能体不会反隐的弱点,并通过建造隐刀成功击败了它。

DeepMind 发推称已达到 Grandmaster 水平。
在今年夏天线上和线下的一系列比赛中,AlphaStar 暂时没像前辈 AlphaGo 那样一举击败“人类界最强选手”,但仍然在与全球顶级玩家的 90 场比赛中取得了 61 场胜利。
基于在游戏对战上的表现,谷歌旗下公司在星际争霸 2 上的研究或许可以在数字助理、自动驾驶,乃至军事战略为人类带来帮助。
星际争霸:人工智能的“下一个重大挑战”
星际争霸 2 是人类游戏史上最困难、最成功的即时战略游戏,这一系列游戏的历史已经超过 20 年。星际争霸长盛不衰的部分原因在于其丰富的多层次游戏机制,对于人工智能研究来说,这是一个非常接近现实世界的虚拟环境。
自从围棋、国际象棋、德州扑克相继被计算机破解以来,星际争霸被视为人工智能的“下一个重大挑战”。
星际争霸 2 巨大的操作空间和非完美信息给构建 AlphaStar 的过程带来了巨大挑战。与围棋不同,星际争霸 2 有着数百支不同的对抗方,而且他们同时、实时移动,而不是以有序、回合制的方式移动。国际象棋棋子符合规则的步数有限,但 AlphaStar 每时每刻都有超过 1026 种动作选择,即操作空间非常巨大。而且,与围棋等完美信息游戏不同,星际争霸 2 是非完美信息游戏,玩家经常无法看到对手的行动,因此也无法预测对手的行为。
2017 年,DeepMind 宣布开始研究能进行即时战略游戏星际争霸 2 的人工智能——AlphaStar。事实上,根据 DeepMind 博客提供的信息,DeepMind 对星际争霸的研究已经超过 15 年。也就是说,对整个星际争霸游戏智能体的研究早在 2004 年之前就开始。
2018 年 12 月 10 日,AlphaStar 击败了 DeepMind 公司里的最强玩家 Dani Yogatama;到了 12 月 12 日,AlphaStar 已经可以 5:0 击败职业玩家 TLO 了(TLO 是虫族玩家,据游戏解说们认为,其在游戏中的表现大概能有 5000 分水平);又过了一个星期,12 月 19 日,AlphaStar 同样以 5:0 的比分击败了职业玩家 MaNa。
至此,AlphaStar 又往前走了一步,达到了主流电子竞技游戏顶级水准。
排名前 1%,“神族、人族、虫族”均达到大师水平
DeepMind 称,AlphaStar 本次研究和以往有以下不同:
AlphaStar 有着和人类玩家一样的摄像头视野限制(即机器也看不到视野外发生的情况),而且机器动作频率也被限制住了。
AlphaStar 能够玩一对一匹配中的三个种族了(即星际争霸中的人族、神族和虫族),而且每个种族的时候都会有一套对应的神经网络。
整个训练过程是完全自动化的,智能体从监督学习开始训练,而不是从过去实验过的智能体开始。
AlphaStar 在 Battle.net 对战平台上进行了游戏,使用的是和人类玩家一样的地图。
DeepMind 使用通用机器学习技术(包括神经网络、借助于强化学习的自我博弈、多智能体学习和模仿学习)直接从游戏数据中学习。据《Nature》论文中描述,AlphaStar 在 Battle.net 上的排名已超越 99.8%的活跃玩家,并且在星际争霸 2 的三场比赛(神族、人族和虫族)中都达到了大师级水平。研究者希望这些方法可以应用于诸多其他领域。
基于学习的系统和自我博弈显著促进了人工智能的显著进步。1992 年,IBM 的研究人员开发出了 TD-Gammon,结合基于学习的系统与神经网络玩西洋双陆棋(backgammon)。TD-Gammon 不是根据硬编码规则或启发法来玩游戏,而是在设计上使用强化学习并反复试验,找出如何获得最大化胜率。开发人员利用自玩对弈的概念使得系统的鲁棒性更强:即通过与自身版本进行对抗,系统变得越来越精通游戏。当结合起来时,基于学习的系统和自我博弈的概念提供了开放式学习的强大范式。
从那以后,诸多进展表明,这些方法可以扩展到其他挑战日益增多的领域。例如,AlphaGo 和 AlphaZero 证实了系统可以在围棋、国际象棋和日本将棋等游戏中,展现人类所不能及的能力。OpenAI Five 和 DeepMind 的 FTW 也在 Dota 2 和《雷神之锤 III》现代游戏中展现了自我博弈的强大性能。
DeepMind 的研究者潜心于开放式学习的潜力及局限性研究,开发出既鲁棒又灵活的智能体,从而可以应对复杂的现实世界环境。星际争霸之类的游戏是推进这些方法的绝佳训练场,因为玩家必须使用有限的信息来做出灵活有难度的决策。
在智能体“联盟”中进行的自我博弈
Deepmind 发现,AlphaStar 的游戏方式令人印象深刻——这个系统非常擅长评估自身的战略地位,并且准确地知道什么时候接近对手、什么时候远离。虽然 AlphaStar 已经具备了出色的控制力,但它还没有表现出超人类的能力,至少没有到那种人类理论无法企及的高度——总体来说还是公平的,与它对战的感觉就像平时星际争霸真实对战的场景。
即使取得了成功,自我博弈会存在缺陷:能力确实会不断提升,但它也会忘记如何战胜之前的自己。这可能会造成“追尾”(像小狗那样自己追着自己的尾巴),从而失去了真正的提升机会。
比如说,在石头剪刀布的游戏中,一个人可能更喜欢出石头,在游戏玩法提升过程中,它会变成爱出剪刀,后来又变成了爱出石头。进入与所有游戏策略的对战是解决虚拟自我博弈此前存在问题的途径。
在首次将 StarCraft II 开源后,Deepmind 发现虚构的自我博弈不足以训练出强大的战术,于是他们尝试开发更优的解决方案。
“联盟”训练
在最近这期《Nature》杂志中,Deepmind 文章的中心思想是将这种虚构的自我博弈扩展到一组智能体,即“联盟”。通常,在自我博弈中,想在星际争霸游戏中取得更好成绩的玩家可以选择与朋友合作战斗,来训练特定的策略,因此他们所面对的竞争对手并不包括这个游戏中所有的玩家,而是帮助他们的朋友暴露问题,使其成为更好更鲁棒的玩家。
联盟这一概念的核心思想是:仅仅只是为了赢是不够的。相反,实验需要主要的智能体能够打赢所有玩家,而“压榨(exploiter)”智能体的主要目的是帮助核心智能体暴露问题,从而变得更加强大。这不需要这些智能体去提高它们的胜率。通过使用这样的训练方法,整个智能体联盟在一个端到端的、完全自动化的体系中学到了星际争霸 2 中所有的复杂策略。
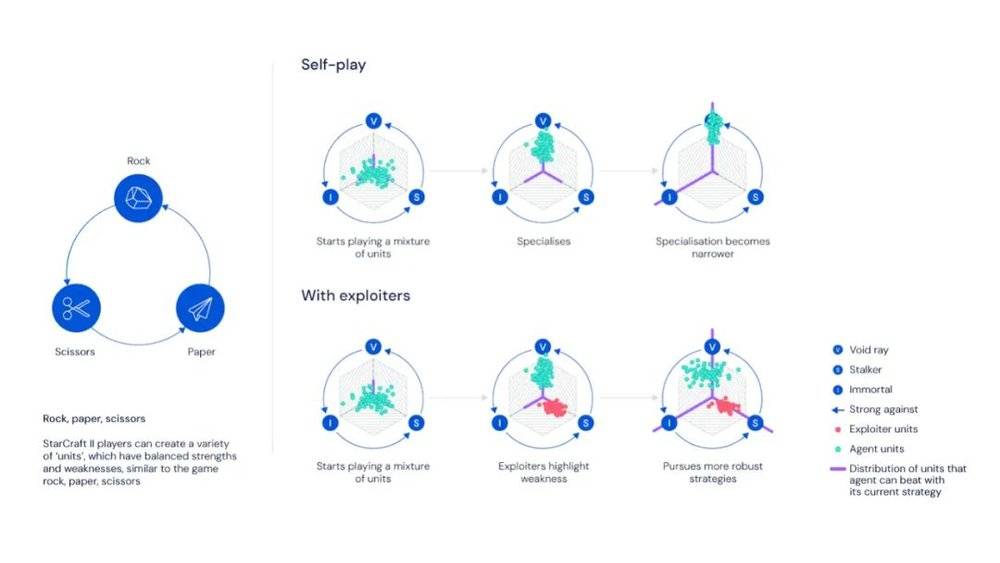
星际争霸系列等复杂游戏域中的一些挑战。
(前排)玩家可以创建各种“单位”(如工人、战士或运输者)来部署不同的战略移动。得益于模仿学习,DeepMind 的初始智能体可以执行多种策略,在这里描述为游戏中创建的单位组成(在此示例中:虚空舰、追踪者和不朽者)。但是,由于某些策略更易于改进,因此单纯的强化学习主要集中于它们。其他策略可能需要更多的学习经验或者具有一些特殊的细微差别,使得智能体更加难以完善。这就会造成一个恶性循环,其中一些有效策略的效果越来越差,因为智能体放弃了它们而选择了占主导地位的策略。(底部行)研究者在联盟中添加了一些智能体,这些联盟的唯一目的是暴露核心智能体的弱点。这意味着需要发现和开发更多有效的策略,从而使核心智能体对敌方产生更多的抵抗。在同一时间,研究者采用了模仿学习技术(包括蒸馏法),以防止 Alphastar 完全摆脱训练,并使用隐变量来表征多样化的开局行动。
在星际争霸等复杂的环境中,探索是另一项关键挑战。每个智能体在每个时间步中最多可以使用 1026 个可能的动作,并且在了解自己赢得或输掉比赛之前,该智能体必须先进行数千次动作。在如此庞大的解决空间(solution space)中,寻找制胜策略是一项挑战。即使拥有强大的自我博弈系统以及由压榨智能体组成的多样化联盟,但如果没有一些先验知识,系统在如此复杂的环境中也几乎不可能制定出成功的策略。
因此,学习人类玩家的策略并确保智能体在自我博弈中不断探索这些策略,这是释放 AlphaStar 效能的关键。为此,借助于模仿学习并结合了用于语言建模的高级神经网络架构和技术,研究者制定了最初的策略,使游戏结果优于 84%的活跃玩家。此外,研究者还使用了一个隐变量,该变量确定了策略并对人类游戏的开局行动分布进行编码,这有助于保留高级策略。然后,AlphaStar 在整个自我博弈中使用一种蒸馏形式(form of distillation),将探索偏向于人类策略。这种方法使得 AlphaStar 可以在单个神经网络中(每个族群各一个)表征许多策略。在评估过程中,这种神经网络不以任何特定的开局行动为条件。
AlphaStar 是一个不同寻常的玩家,其具有最佳玩家的反应能力和速度,还有其战略和风格是完全独有的。AlphaStar 的训练是通过一组智能体在联盟相互竞争,压榨出所有可能的结果,使得游戏结果变得难以想象般的不同寻常。这无疑使人想要思考星际争霸中有多少可能性是职业玩家已经探索过的。
另外,研究者还发现许多之前强化学习学到的方法是无效的,因为这些方法的动作空间太大。特别的是,AlphaStar 使用了异步强化学习(off-policy reinforcement learning),使其可以高效地更新自己之前的策略。
实验效果
在测试 AlphaStar 的过程中,DeepMind 的研究者对其进行了限制,使其和人类玩家保持一致。特别是在操作速率上,为了避免智能体为了多获得奖励而像超人一样过快点击从而打败对手,DeepMind 将其控制在有经验的玩家水平上。
基于这些限制,经过了 27 天的训练后,DeepMind 与暴雪在战网天梯中开放了 AlphaStar:玩家只要进行申请并通过就可以和这个最强 AI 进行在线对决了。而且现在,AlphaStar 已经可以使用全部三个种族。在开放对战环境中,AlphaStar 在欧洲服务器上排名 top0.5%。
尽管 AlphaStar 已经取得了不错的成绩,但是它并没有完全打败顶尖水平的人类玩家。此外,仍有一些 AlphaStar 在训练过程中没有暴露出来的弱点,这些都是需要继续改进的。
今年 9 月,DeepMind 和暴雪放出了 AlphaStar 在天梯上与各路顶级玩家交手的视频,其中不乏当世排名前 10 的职业选手。
这可能是目前最为高端的“人机大战”了:AlphaStar vs Serral。
DeepMind 当然也碰上了目前星际争霸 2 最强的玩家,芬兰虫族选手 Serral。在这场 16 分钟的比赛里,Serral 和 AI 进行了正面的硬碰硬战斗。然而看起来在这种比赛里任何一方出现短板就会造成最终的失利。有评论表示:看起来 Serral 比 AlphaStar 更像是 AI。
军方可能会感兴趣
尽管 DeepMind 表示,他们永远都不会让这项研究卷入军事领域,而且星际争霸 2 并不是一个现实战争的模拟,但谢菲尔德大学 AI 和机器人学教授 Noel Sharkey 表示,但(DeepMind 的)结果会引起军方的注意。今年 3 月份,美国政府发布的一份报告描述了 AI 如何丰富战争模拟以及帮助战争玩家评估不同战术的潜在后果。
“军事分析人士肯定会将 AlphaStar 实时战略的成功视为 AI 用于作战规划优势的一个明显例子。但这是一个极度危险的想法,可能会带来人道主义灾难。AlphaStar 从某个环境的大数据中学习战略,但来自叙利亚、也门等冲突地区的数据太少,无法使用。”Sharkey 表示。
“正如 DeepMind 在最近的一次联合国活动中所说的,这种方法对于武器控制来说将是非常危险的,因为这些举动无法预测并且可能以意想不到的方式发挥作用——这违反了管辖武装冲突的法律。”
Nature 论文:
https://www.nature.com/articles/s41586-019-1724-z
https://storage.googleapis.com/deepmind-media/research/alphastar/AlphaStar_unformatted.pdf
AlphaStar 对战录像:
https://deepmind.com/research/open-source/alphastar-resources
参考内容:
https://www.nature.com/articles/d41586-019-03298-6?utm_source=twt_nnc&utm_medium=social&utm_campaign=naturenews&sf222555256=1
https://www.deepmind.com/blog/article/AlphaStar-Grandmaster-level-in-StarCraft-II-using-multi-agent-reinforcement-learning
本文来自公众号:机器之心(ID:almosthuman2014)。

 02:36
02:36






 13:53
13:53



 06:21
06:21
 04:54
04:54
 12:58
12:58
 17:21
17:21
 23:16
23:16
 08:14
08:14
 12:32
12:32
 14:23
14:23




