2024-03-11 08:36


扫码打开虎嗅APP

本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究,题图来自:视觉中国
整整八年前,阿法狗(AlphaGo)首次战胜人类顶尖棋手之一、韩国九段李世石。
在从2016年3月9日到15日的总共五番棋的对决中,阿法狗四胜一负,创造了人工智能发展史上的一个里程碑。
OpenAI负责推理研究的科学家布朗(Noam Brown),在社交媒体平台X上发了一条推文,纪念这一事件。
“与典型的神经网络不同,AlphaGo在每一步着法上花费约1分钟时间,通过搜索来改进其策略。这使得AlphaGo的实力超过了比它大1000倍的单纯模型。即使在今天,也没有人训练出一个单靠原始神经网络就能在围棋中超越人类的系统。”
听到了没有,1. 胜过了比它大上千倍的模型。2. 仅靠神经网络的扩展,并不能解决问题。
AlphaGo之所以能取得如此卓越的成就,关键在于它将神经网络和搜索树相结合。神经网络为搜索树提供了高质量的评估函数,而搜索过程又反过来使神经网络在自我对弈中不断强化和改进。通过这种相互增强的循环,AlphaGo最终达到了远超人类水平的围棋实力。
这一创举不仅彰显了当时人工智能的突破性进展,还为更为复杂的决策领域的智能算法研究指明了方向,即有效结合机器学习和搜索算法的力量,而不是单纯依赖大型模型。
树搜索(tree search)是一种在决策过程中广泛使用的算法,用于在树状结构中查找具有某些预定义特征的节点。
在AlphaGo的情况下,树搜索是指在围棋对弈中,AlphaGo会根据当前棋局,构建一棵包含大量可能走法和后续局面的树状结构。然后AlphaGo使用评估函数(通常由训练好的神经网络提供)对树中的每个节点(即局面)进行评分,再基于这些评分结合搜索策略(如Monte Carlo树搜索),逐步向下遍历和剪枝,最终选择一个最佳着法。
这种树搜索过程实际上是在有限的计算资源下,有效地探索和评估局面树中可能的行棋路线,以找到最优解。通过结合深度神经网络提供的强大评估能力,AlphaGo的树搜索可以比传统的基于规则的搜索策略更准确地预测一手棋的分数,从而做出更明智的着法选择。
总的来说,树搜索算法使AlphaGo能够在庞大的可能着法空间中高效搜索,并通过神经网络评估函数指导搜索方向,最终达到超人类水平。
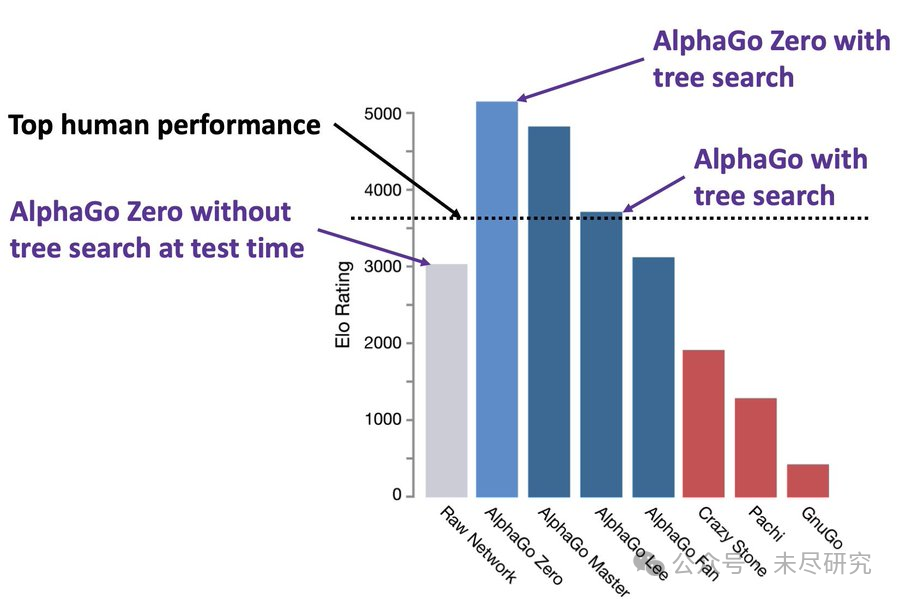
上图比较了不同人工智能系统在围棋游戏中的表现,主要是AlphaGo的各个变种,它们的表现是用国际象棋等级评分系统Elo分数来衡量的。
顶尖人类棋手的Elo分数大约在4000分左右。在测试时期,不使用树搜索的AlphaGo Zero的表现已经相当强,但仍低于顶尖人类水平。加入树搜索技术后,AlphaGo Zero的表现大幅提升,超过了顶尖人类水平。
在去年传得沸沸扬扬的OpenAI的Q*模型中,其主角正是布朗。
布朗从Meta加入OpenAI前,发了一则推文:“多年来,我一直在研究AI自我对弈和推理,比如在扑克和外交游戏中。现在,我将研究如何使这些方法真正通用。”
布朗曾在DeepMind实习时参与过AlphaGo的项目,布朗认为,在AlphaGo和布朗的扑克软件中使用的搜索方法特定于那些特定的游戏,“如果我们能发现一个通用版本,好处将是巨大的。是的,推理可能会慢1000倍,成本更高,但我们会为一种新的抗癌药物支付多少推理成本?或者为了证明黎曼假设?”
Meta的首席AI科学家杨立昆认为布朗正在研究Q*。
OpenAI对试图把大型语言模型与AlphaGo风格的搜索树结合起来感到兴奋,希望这将使计算机能够进行类似开放式的智力探究。
但把GPT与AlphaGo结合起来,至少需要克服两个大挑战。
第一个挑战是找到一种方法让大型语言模型进行“自我对弈”。像AlphaGo那样,通过与自己下棋并从输赢中学习。例如,OpenAI让其魔方软件在模拟的物理环境中练习,根据模拟的魔方是否最终达到“解决”状态来判断哪些动作是有帮助的。
理想的情况是,大型语言模型能够通过类似自动化的“自我对弈”来提高其推理技能。但这需要一种方法来自动检查特定解决方案是否正确。如果系统需要一个人来检查每个答案的正确性,那么训练过程不太可能达到与人类竞争的规模。
直到2023年5月,OpenAI发表的论文中显示其仍在雇佣人类来检查数学解决方案的正确性。之后人们传闻,OpenAI可能在这方面已经取得了突破,在基础数学方面取得了显著提高。最近推出的Claude3,在数学方面的成绩也有显著提升。
如果GPT-5或GPT-4.5取得了突破,这一方面就很值得期待了。
参考:
Mastering the game of Go without human knowledge, David Silver,et al
The real research behind the wild rumors about OpenAI’s Q* project, Timothy B. Lee
本文来自微信公众号:未尽研究 (ID:Weijin_Research),作者:未尽研究

 12:11
12:11









 06:21
06:21
 17:57
17:57
 13:10
13:10
 12:58
12:58
 05:47
05:47
 14:40
14:40
 15:55
15:55
 03:11
03:11
 25:37
25:37

