2020-08-05 16:25


扫码打开虎嗅APP

生命、宇宙和万物的奥秘究竟是什么,是4.398 万亿个参数?GPT-3的究极进化就是AGI吗?AI大佬们为此还产生了分歧。本文来自微信公众号:新智元(ID:AI_era),编辑:梦佳、白峰,题图来自:电影《终结者3》
生命、宇宙和万物的奥秘究竟是什么?
数学家说是来自于根号、方程式和复杂的函数;天体物理学家说来自量子纠缠、原子核裂变、白矮星坍缩;生物学家说来自DNA、RNA......
而AI大佬却说,是来自4.398万亿个参数而已。
除非你一直在火星上度假,否则你肯定注意到了GPT-3。
AI大佬们谈GPT-3:生命、宇宙和万物的答案,就只是 4.398 万亿个参数而已
在GPT-3论文发表不久,神经网络之父Geoffrey Hinton对最近媒体追捧的有1750亿个参数的语言训练模型GPT-3 的评价:“鉴于 GPT-3 在未来的惊人前景,可以得出结论,生命、宇宙和万物的答案,就只是 4.398 万亿个参数而已”。

但是著名的人工智能研究者Gary Marcus,发表最新见解,认为GPT-3压根不了解它所谈论的世界,you know nothing, GPT-3......

进一步增加语料库只能让它产生那些看起来更可信的七拼八凑的话语,但无法弥补其对世界根本性理解的缺失。将来出了GPT-4,也还是会需要人工干预和筛选。
言外之意,尽管增加了这么多的参数,也只是表面上看“懂”得多了许多,但这种“懂”是没有灵魂和内核的,并没有从本质上破解人类世界的奥秘。
起因是其中一个读者提到,cherry-picking是一个巨大的问题,cherry-picking指的是人为的精挑细选,比如通顺有趣的句子。
“大部分GPT-3的样例都是人工筛选的”。目前的结果只是把光鲜亮丽的cherry呈现在了眼前,还有一大堆成千上万的bad case怎么不说。
cherry-picking的问题其实早已有之。
去年年底,《经济学人》杂志发表了对 OpenAI 的 GPT-2 文本生成系统的采访,当时故意说 GPT-2 给出的这些回答“未经编辑”,而实际上,每个回答都是从生成的 5 个候选回答中由人类挑选的,挑选标准是要语意连贯而且幽默。看了这篇报道,原本以为AI已经能和人类自如对话了,但其实只是一场作秀。
当然Gary Marcus这么认为不无道理。
他一直以来对深度学习领域的学术和应用成果持怀疑态度,这么“泼冷水”也不是一次两次了,为此也经常和其他大佬撕。
Marcus在此前的电话采访中表示,我认为需要以一种哲学家们乐于接受的方式,以及经典人工智能领域的人们有时会采用的方式,对世界进行非常仔细的分析,但不是只知道用正确的工具。”
他还曾经批判,“现在人工智能,人们就知道一味地追求更多的数据和更快的机器。”
也有读者进行了讽刺地回复,20年后的新闻:深度学习能够治疗癌症。
Gary Marcus:这个算法根本不能理解蛋白质的反应性......
都能治疗癌症了,还要啥自行车?

GPT-3在进化:可生成高级论点,写热搜文章,还能构建AI模型
不论两位大佬孰是孰非,随着GPT-3的不断进化,GPT-3会不断产生新的应用是不争的事实。
当GPT-3达到人类数量的神经元后,会变的和人一样聪明吗?
像所有的深度学习系统一样,GPT-3在数据中寻找模式,然后在神经元中更新权重。
为了简化这事,GPT-3已经训练了一个巨大的文本语料库,从海量文本中挖掘统计规律。这些规律对人类来说是未知的,它们以向量的形式被存储为 GPT-3神经网络中不同节点之间的数十亿个权重连接中。
GPT-3革命性的一点在于,这个过程不需要人工干预, 程序在没有任何先验指导的情况下就能自动查找和发现模式,然后用这些模式来完成文本生成。
如果你在 GPT-3中输入单词“fire”,它会推测到单词“ truck”和“ alarm”比“ lucid”或“ elvish”出现的概率更大,一切都很简单。
吞噬了巨大的文本之后,GPT-3的知识深度和复杂性都远超常人。
可生成高级论点,能自我反省
哥伦比亚大学的认知神经科学家拉斐尔 · 米利埃做了一个实验,他把一篇关于GPT-3的论文输入给 GPT-3并要它对论文做出回应。
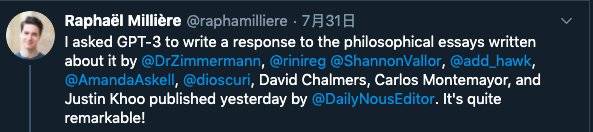
有趣的是,生成的文本不仅有高级的论点,甚至还有自我反省: “人类哲学家经常犯这样的错误,即假设所有的智能行为都是一种推理形式。这是一个很容易犯的错误,因为推理确实是大多数智能行为的核心。然而,智能行为也可以通过其他机制产生。我缺乏长期记忆力。每次我们的谈话重新开始,我就会忘记以前发生的一切”。

确实有很多人质疑GPT-3的写作能力,但是伯克利大学的Liam Porr用事实证明,GPT-3是有实用价值的。
牛刀小试,首发就上热搜
你写的文章上过热搜吗?他用GPT-3生成的第一篇文章,就登上了当天hackernews的热榜!
他会给文章写标题和介绍,添加照片,其他的内容由 GPT-3来完成。这篇博客现在有超过26000的访问量,获得了大约60个忠实粉丝,真的是涨粉利器!
自动构建图片分类模型,生成Keras代码
写写前端代码,并不能充分展现GPT-3的代码能力,现在有网友做出了一个可以直接生成Keras模型的应用,你告诉GPT-3想要一个图片分类模型,图片的格式,Keras模型就自动生成了。
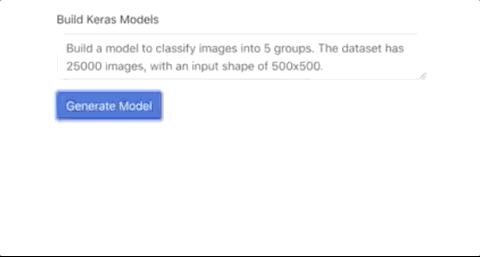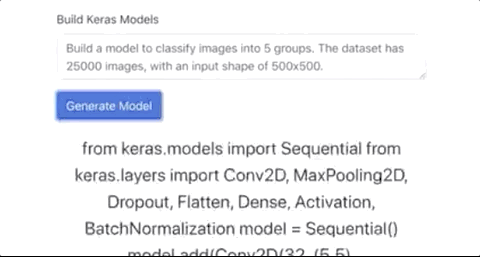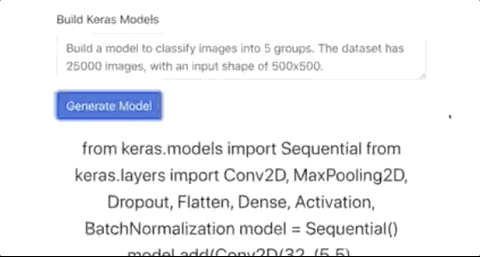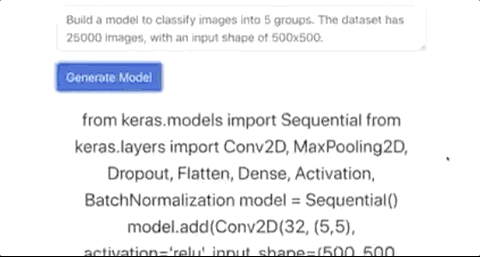
尽管 GPT-3可以编写代码,但是很难判断它的整体实用性。代码是不是很乱?代码是否会给人类开发人员带来更多的问题?没有详细的测试很难说,也许一些bad case被刻意隐藏了。
但是大框架基本是没问题的,即便加上人工的修改时间,GPT-3作为一个辅助工具,也极大地提高了工程师的生产力。
有微博网友表示,GPT-3这样的大模型会让很多人失业。
对人工智能行业来说,算法工程师不会受到大的冲击,但是“调参侠”们可要上点心了。通用的人工智能还有很久,但特定领域通用的代码实现起来就没那么难了。
GPT-n的终极模式:通用人工智能?
通用人工智能(AGI)是 AI 研究的究极目标。这个目标何时能实现?此前在一次对全球23位顶尖AI学者的一次调查中,最乐观的人给出的时间为2029年,最悲观的人认为要到2200年。平均来看,这个时间点为2099年。AGI是真正的有生之年系列。

其实Hinton和Marcus两位大佬的分歧焦点最终要落在: 我们能否用现有的GPT-3来构建 AGI(通用人工智能),或者我们需要在哪些基础性研究中取得突破?
对于这个问题,人工智能从业者们没有一致的答案。
一方面,GPT-3缺少创造人工智能的关键组成部分,计算机在接近人类智能水平之前,需要理解诸如因果之类的东西。
另一方面,通过简单地向GPT-3扔更多的数据和算力,这些模型确实会带来更大的性能提升。
计算机科学家Rich Sutton在一篇名为《苦涩的教训》(The Bitter Lesson)的文章中提出了一种观点,他指出,当研究人员试图基于人类知识和特定规则创建人工智能时,往往会失败。

GPT-3代表着人类向 AGI 迈出了一小步,但这一小步并非微不足道,因为这个模型是非监督学习的。
它吃进无限的原始数据 ,而且每次都会有进步,它的知识是人类知识的总和,可以用你最喜欢的方式跟你交流,接下来,它会不会建立一个“世界模型”,变的无所不知?
未来还会有GPT-4,GPT-5,GPT-n值得期待。
本文来自微信公众号:新智元(ID:AI_era),编辑:梦佳、白峰

 12:58
12:58









 08:45
08:45
 05:47
05:47
 12:11
12:11
 17:57
17:57
 31:30
31:30
 15:28
15:28
 25:37
25:37
 20:24
20:24
 01:21:14
01:21:14




