2020-08-11 17:23


扫码打开虎嗅APP

本文来自微信公众号:大数据文摘(ID:BigDataDigest),作者:牛婉杨,题图来自:游戏《超级马里奥兄弟》
马里奥的系列游戏自打诞生以来就风靡全球,同时也陪伴了无数人的童年。
人工智能出现后,不少技术咖都开始尝试,能不能利用AI完成马里奥的一次通关梦?
比如,这里有一位马里奥游戏疯狂爱好者uvipen就在GitHub上贡献了两种不同的方法,都能让马里奥轻松游走在障碍之间!去年6月,uvipen从2016年的论文“Asynchronous Methods for Deep Reinforcement Learning”中得到了启发,用异步优势Actor-Critic算法(A3C)让马里奥顺利通过了32关中的9关。
显然,他对之前的方法不够满意,于是经过一年多的钻研,他带着新方法来了!这次,他用OpenAI公布的近端策略优化 (Proximal Policy Optimization,简称PPO)算法,成功助力马里奥通过32关中的29关,近乎通关!
效果大概是这样:
强迫症表示这也太舒适了吧,快来和文摘菌一起看看uvipen是如何做到的吧~
用PPO算法顺利通过29关!如果不行,那就换一个学习率
这个PPO是何来头?文摘菌也去了解了一下。
PPO全称是近端策略优化,听这个名字你可能觉得陌生,但是在人工智能圈,这个算法可是早就用于各种游戏对抗中了。
早在2017年,OpenAI 2017年提出的用于训练OpenAI Five的算法就是PPO,也正是在它的帮助下,人工智能OpenAI Five首次在电子竞技游戏DOTA 2国际邀请赛中打败世界冠军Dendi。

Dendi在第一局比赛中以2:0告负,而第二局仅开始十分钟Dendi就选择了直接认输。
由此看来,PPO的强大之处可想而知,它不仅具备超强的性能,且实现和调优要简单得多。这也正是uvipen选择使用PPO训练马里奥通关策略的原因。接下来文摘菌就为你介绍一下PPO~
近端策略优化(PPO),是对策略梯度(Policy Graident)的一种改进算法。Policy Gradient是一种基于策略迭代的强化学习算法,PPO的一个核心改进是将Policy Gradient中On-policy的训练过程转化为Off-policy,即从在线学习转化为离线学习。
举一个比较通俗的例子,On-policy就好比你在下棋;而Off-policy就相当于你在看别人下棋。
而这个从在线到离线的转化过程被称为Importance Sampling,是一种数学手段。

https://openai.com/blog/openai-baselines-ppo/
uvipen把代码都放在了Github上,如果你也想成为马里奥的开挂式玩家,可以运行python train.py来训练你的模型。例如:python train.py --world 5 --stage 2 --lr 1e-4 。
然后通过运行python test.py来测试训练后的模型。例如:python test.py --world 5 --stage 2。
如果在训练过程中遇到问题,可以尝试换一个学习率。uvipen通常把学习率设为1e-3,1e-4或1e-5,但是也有一些比较难的关卡,比如第1~3关,就连uvipen都失败了70次,不过当他最后将学习率调整为7e-5后,终于过了这关~
那既然一共完成了29关,剩下的3关分别是哪些呢?作者表示,只有4-4、7-4和8-4这三关没过去,因为这些关都比较难,要求按一定规律才能过去,玩家必须选择正确的道路前进,如果你选错了路就会陷入“死循环”,从而无法过关。
比如7-4这一关就要先从下面走一次再从上面走才能过,否则就会一直重复,因此在行进过程中一旦发现重复就一定是错了,需要赶紧换路线。

这一关也被不少玩家称为,马里奥世界中最难迷宫。

不得不说,这对于AI确实十分有挑战性,只通过PPO算法是无法完成的,还需要进一步研究。在这里文摘菌就坐等uvipen更新啦,相信未来他一定能够利用AI完美通关马里奥~
Github指路:https://github.com/uvipen/Super-mario-bros-PPO-pytorch
去年尝试用A3C通关失败,但是科普很成功
其实uvipen想要用人工智能通关马里奥也没有那么容易。在去年他就开始了尝试,当时,uvipen使用的是异步优势Actor-Critic算法(A3C),虽然只过了9关,但还是在当时引起了一番讨论。
uvipen自称是受到2016年这篇论文“Asynchronous Methods for Deep Reinforcement Learning”的启发,于是就想用其中提到的异步优势Actor-Critic算法(A3C)来尝试一番。

论文链接:https://arxiv.org/pdf/1602.01783.pdf
uvipen发现,在他去年实现这个项目之前,已经有几个存储库在不同的常见深度学习框架(如Tensorflow、Keras和Pytorch)中可以很好地重现论文的结果。他认为这些框架都很好,只不过在图像预处理、环境设置和权重初始化等很多方面都过于复杂,会分散用户的注意力。
因此,他决定写一个更干净的代码,简化那些不重要的部分,同时仍然严格遵循论文中的方法。
来看看在A3C的加持下马里奥是怎么过关的:
这简直就是“乘风破浪的马里奥”啊~ 不过也有网友打趣到:“马里奥里的各种隐藏彩蛋这下就都不能被发现啦”“不吃掉所有蘑菇的马里奥没的灵魂”“应该研究一下如何顺利通关的同时拿到所有分”
虽然通关没成功,但是uvipen还是特意为了照顾那些不熟悉强化学习的朋友,在他的Github上将A3C分解为更小的部分,并用通俗的语言解释了什么是A3C算法,以及是如何通过这一算法实现的。
文摘菌也借此机会帮大家复习下什么是Actor-Critic算法。
我们不如这样想,你的agent有两个部分,Actor(演员)和Critic(评论家),Actor就好比一个淘气的小男孩正在大胆探索着他周围奇妙的世界,而Critic就像是他的爸爸一样需要监督着他,只要孩子做了好事,爸爸就会表扬和鼓励他以后再做同样的事。当然,当孩子做错事时,爸爸也会警告他。孩子与世界的互动越多,采取的行动也越多,他从父亲那里得到的正面和负面的反馈也越多。
孩子的目标是,从父亲那里收集尽可能多的积极反馈,而父亲的目标是更好地评价儿子的行为。换句话说,在Actor和Critic之间,有一种双赢的关系。
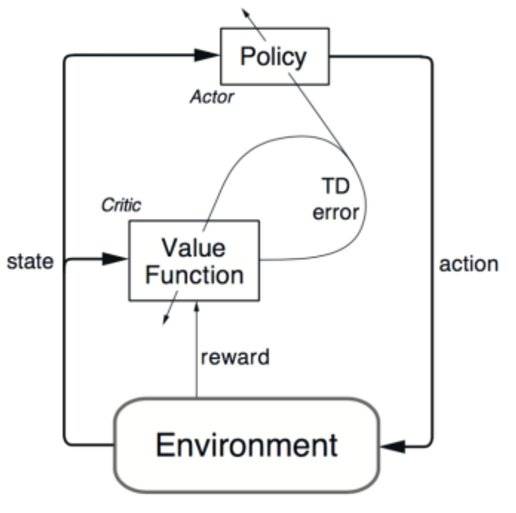
那么优势Actor-Critic算法就相当于为了让孩子学得更快、更稳定,父亲不会告诉儿子他的行为有多好,而是会举例告诉他,与其他行为相比,他这样做好在哪里。有时候一个例子往往胜过千言万语。
接下来要说的就是让马里奥通关的关键所在了!对于异步Actor-Critic优势算法而言,就像是为孩子提供了一所“学校”,有了“老师”和“同学”孩子可以学的更快、更全面。而且,在学校里孩子们还可以合作完成一个项目,他们每个人都可以做着不同的任务,目标却是相同的,这样岂不是效率更高。
同样,uvipen把他用到的相关代码都放在了Github上,感兴趣的小伙伴可以前去了解:https://github.com/uvipen/Super-mario-bros-A3C-pytorch
读到这里,同学们是不是也和文摘菌一样好奇这位同学是何许人也,文摘菌还真查到了~
Viet Nguyen,一位热爱NLP和CV游戏小能手
这位Github用户uvipen正是Viet Nguyen。
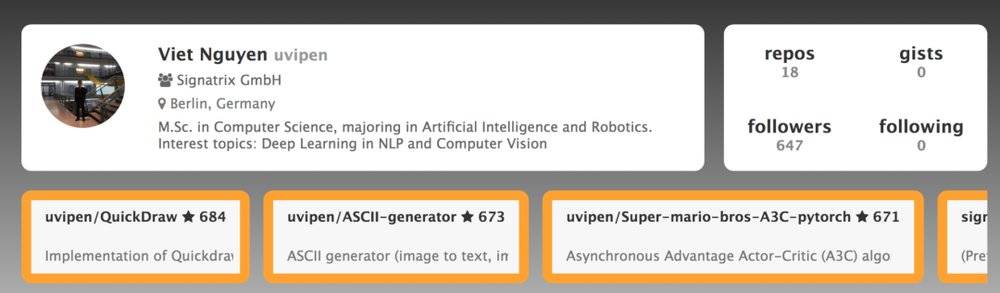
https://www.gitmemory.com/uvipen
原来这位同学拥有计算机科学硕士学位,主修人工智能和机器人技术。主要的研究方向是自然语言处理和计算机视觉。目前身处德国柏林。

在他的个人项目中,一个叫“QuickDraw”的项目获得了684颗星,是他众多项目中最受欢迎的一个。
这是他用Python开发的一款在线小游戏,你可以直接在摄像头前画一些简笔画,比如门、衣服、裤子等容易识别的物体,系统首先能够识别出你在画画,其次能够根据你隔空画的轮廓识别出你画的是什么。
比如,小哥随手就画了个衣服:
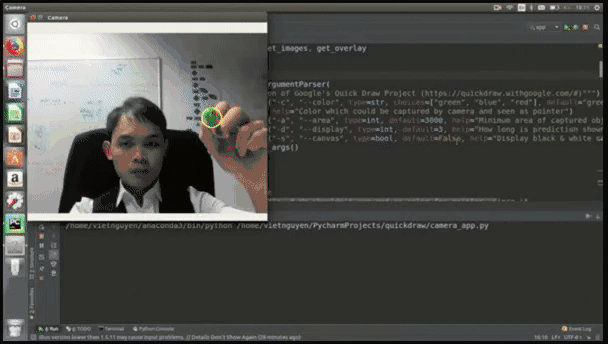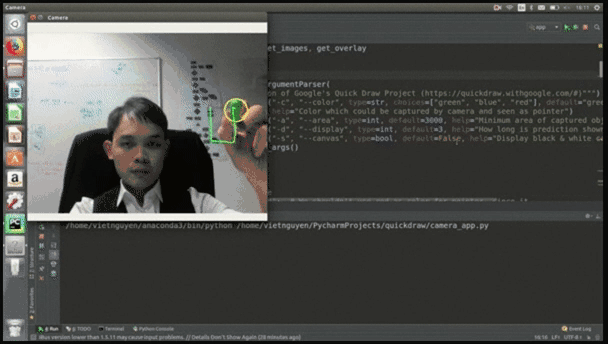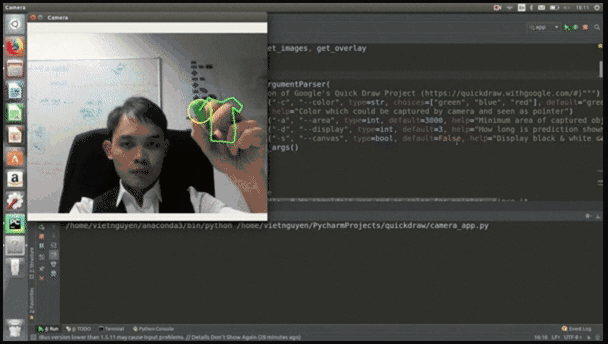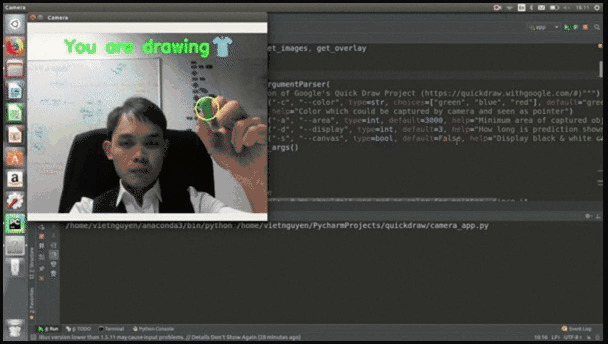
最后,文摘菌给出项目地址,感兴趣的小伙伴可以前去了解:https://github.com/uvipen/QuickDraw
本文来自微信公众号:大数据文摘(ID:BigDataDigest),作者:牛婉杨

 09:44
09:44








 05:47
05:47

 31:30
31:30
 14:41
14:41
 11:18
11:18
 19:42
19:42
 06:37
06:37
 04:39
04:39
 01:21:14
01:21:14
 12:11
12:11




