2020-12-10 09:26


扫码打开虎嗅APP

通过手工推导,我们可以解决包含少量变量的因果推理问题,但对于现实中有几十个或者上百个结点的因果图,当前业界还需要一个可以自动化进行因果推理的演算应用框架。本文整理自中科院计算所在读博士李奉治在集智-凯风研读营的分享,介绍Judea Pearl的因果理论,以及Do-演算在因果推断领域的应用前景。
本文来自微信公众号:集智俱乐部(ID:swarma_org),作者:李奉治 ,编辑:邓一雪,原文标题:《因果阶梯与Do-演算:怎样完美地证明吸烟致癌?》,题图来自:视觉中国
1. 从吸烟致癌谈起
随着香烟的大批量生产和烟厂铺天盖地的广告宣传,在上世纪,香烟的销售量与受众有了突飞猛进的增长。但在1924年,美国《读者文摘》就曾刊载一篇文章,题目是《烟草损害人体健康吗?》,这也是此问题首次出现在大众的视野之中。
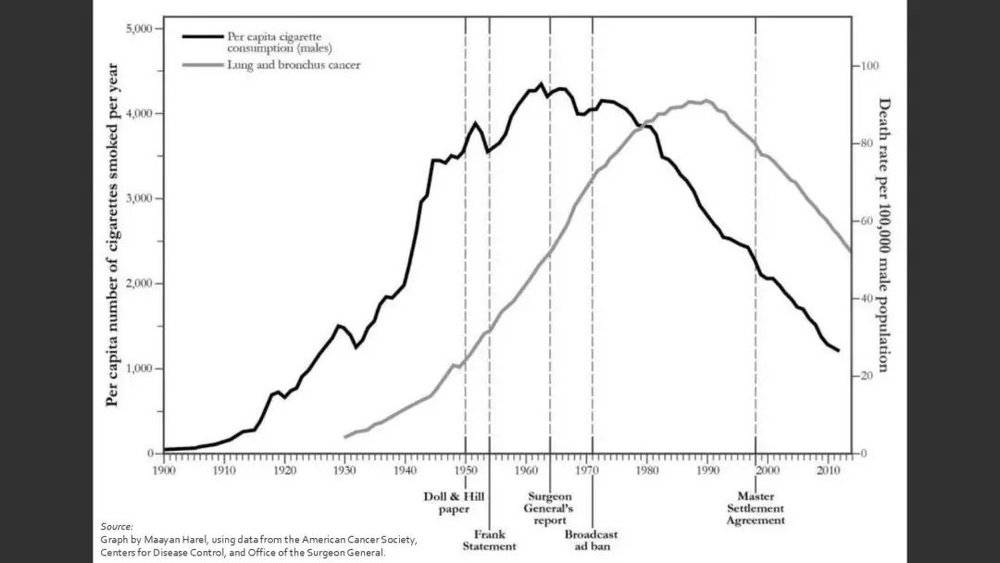
在50年代末,这个问题在统计学家和医生群体中产生了激烈而冲突的讨论。上方这张折线图中的黑线,展示了随着时间的推移,美国男性每年的人均香烟消费量的变化,而灰色的线是肺癌及支气管癌的死亡率。从直观上很容易看出,这两条折线有着几乎一样的形状,时间上有着30年左右的偏移。从时序的相关性上来观察,很多人已经认定,就是吸烟导致了肺癌的发生。
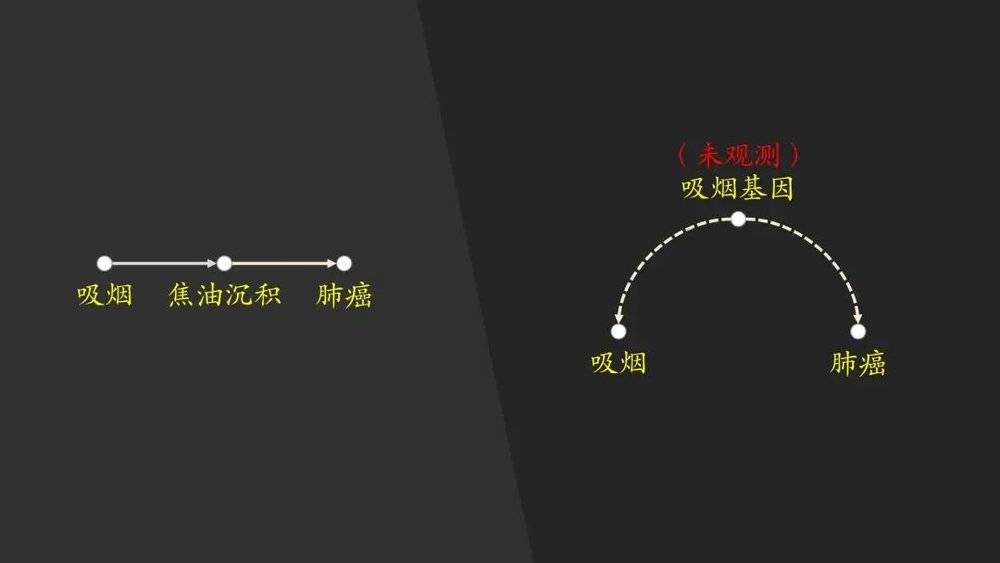
在这里,我们使用图结构来描述这一问题。我们使用一个节点来表示一个变量,节点之间的有向边表示起点节点是终点结点的直接原因。
一部分研究者认为,吸烟与肺癌的关系如左图所示,吸烟会直接导致肺部的焦油沉积,而焦油沉积会直接导致肺癌的产生。这里需要额外说明的是,每一条边上其实是有一个权值的,比如焦油沉积会有0.7的概率直接导致肺癌产生。所以这张图并不是说吸烟就一定会肺癌。
而右侧的图是另一派研究者的观点,他们认为吸烟并不是肺癌产生的原因,而是有一个当时还没有观测到的吸烟基因,既会导致一个人容易尼古丁上瘾,又会导致肺癌的产生,因此吸烟和肺癌两者之间产生了相关性。
那么这两种模型究竟哪一个是正确的呢?按照传统观点,我们就需要开展实验和数据收集,使用统计学的方式来得出结论了。

我们将两个观点结合到一起,就得到了这样的一张图。我们如果要进行实验,验证吸烟基因是否是真正的影响因素,就需要对吸烟基因这个变量进行控制。
一个很朴素的想法就是,我们找到一群被试,通过随机抽签的方式强制他们吸烟或不吸烟,这样就可以排除掉吸烟基因的影响。当然,这从医学伦理的角度来说,是根本不可能做到的。更为棘手的是,还有各种各样新的反对者的观点的提出,比如一个人的心情、整体社会的工业化程度等等,都能成为反驳吸烟导致肺癌这一个因果路径的影响因子。
那么,我们是否真的就永远无法解决这个问题了吗?
2. 基础前置概念
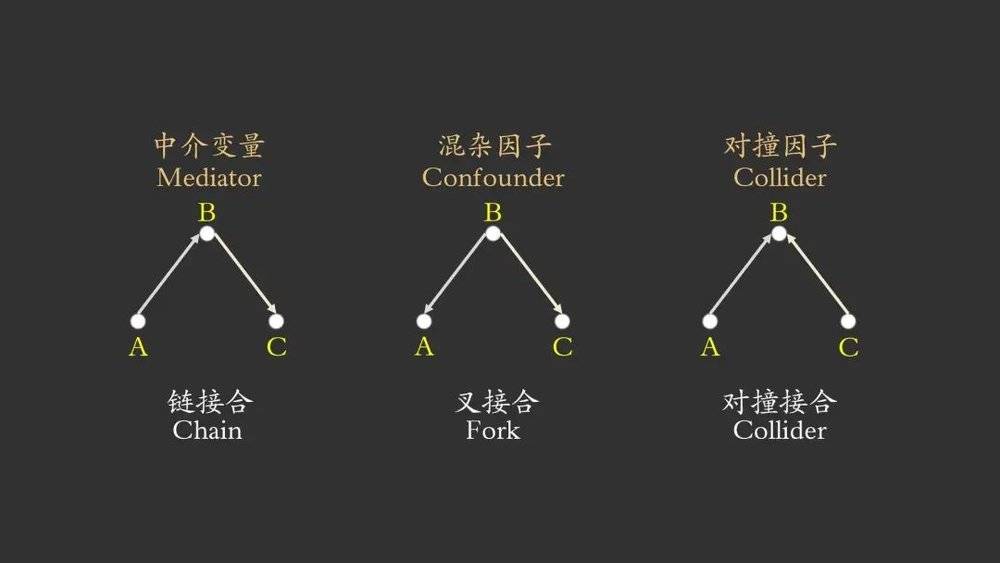
在因果图中,结点之间的有向边可以看做是因果关系传递的通道。为了探寻两个结点之间的因果性关系,十分重要的方法就是研究两者之间所有路径上的因果信息传递状态。对于有向图中的路径,只会有这三种基础结构,对应了“因果流”的三种模式:
1. A→B→C :链(Chain)接合,其中B被称作“中介变量”(Mediator)。
2. A←B→C :叉(Fork)接合,其中B被称作“混杂因子”(Confounder)。
3. A→B←C :对撞(Collider)接合,其中B被称作“对撞因子”(Collider)。
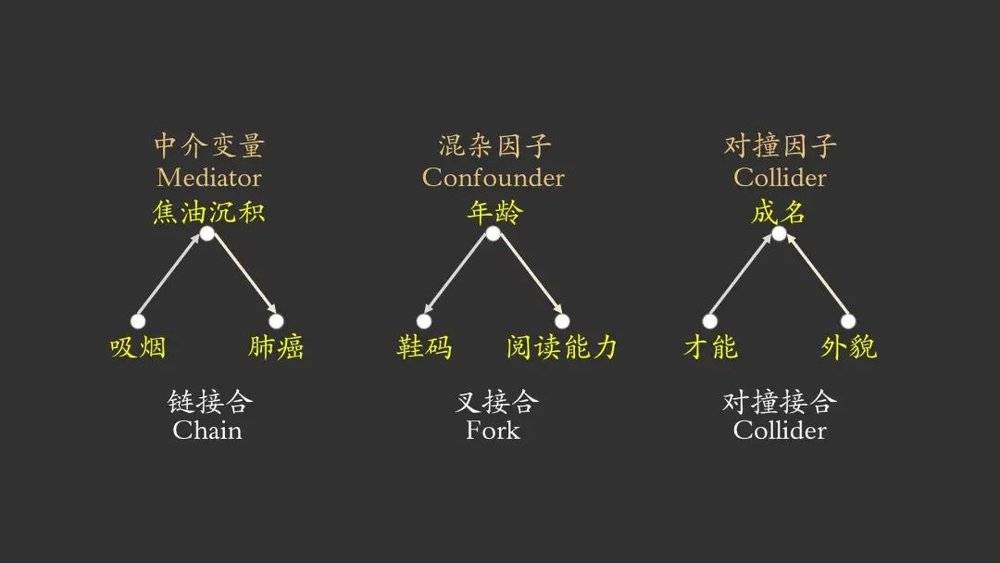
在进行实验时,如果我们控制了某一变量,会怎样影响因果信息的传递呢?上图对于三种接合分别给出了例子。
对于链接合,如果控制了中介变量B,A与C之间的因果关系传递就会被阻断。例如在吸烟导致焦油沉积导致肺癌这个例子中,如果我们控制焦油沉积这个变量,进行分层统计,那么就阻断了吸烟到肺癌的因果传递,无论吸烟的分布是什么样的,都不影响最后肺癌的分布结果。或者说,只要医生发现了某个人的肺部焦油沉积很高,那么无论患者是否吸烟,都不会影响医生对肺癌高风险的判断。
对于叉接合,如果控制了混杂因子B,A与C之间就失去了相关性。给出的例子是一个很有趣的统计学现象,就是对于孩子们来说,往往穿更大鞋码的孩子,阅读能力就越强。其实原因很明显,有“年龄”这个混杂因子,年龄越大的孩子往往会有更大的鞋码和更好的阅读能力。而如果我们控制了年龄这个混杂因子,在每个年龄层面进行分析,就会发现鞋码和阅读能力之间是没有关联的,因果信息传递的路径被切断了。
对于对撞接合,原本A和C之间就是独立的,但如果控制了对撞因子B,根据辩解效应(Pearl, 1988)的存在,反而会打开A与C之间的因果关系传递通道。例如才能和外貌都会让一个成名,而且一个人的是否有才能和一个人是否好看之间往往是没有直接相关性的。但如果我们已经知道了某个人成名了,控制了这一变量,那么才能和外貌之间的因果信息传递就被打开了,当我们知道一个名人很有才能时,就会潜意识上认为这个人可能不会很好看。如果知道了一个人因为外貌而成名,就会觉得这个人可能没有才能。

上方的三种接合模式都有对应的控制因果流的传递方法。那么对于更大的因果图,如何阻断某两个结点之间的因果信息流呢?这里就提供了一个判据,被称为d-分离,具体的定义如图所示。以我们以之前的吸烟的因果图为例,要阻断吸烟和肺癌之间的信息流,那么就需要看两个路径,控制吸烟基因和焦油沉积两个变量,才能使吸烟与肺癌之间满足d-分离。

我们刚才已经尝试用图来表示我们对于知识的信念,在这里我们需要形式化定义之前的操作:概率因果模型(Probabilistic Causal Model)。PCM是一个四元组,包括:
1. 一组外生变量U,这些变量无法被观测或干预,但会影响到模型中的其他变量。在刚才的例子中,吸烟基因就是外生变量,因为在当时的技术下,基因是无法被检测或干预的;
2. 一组内生变量V,这些变量是可以被观测的,例如吸烟、焦油沉积和肺癌。这些变量的值依赖于U∪V的一个子集,例如肺癌变量就是直接依赖于吸烟基因和焦油沉积;
3. 一组函数F,刻画了变量之间的生成关系,在因果图中对应了其中的有向边;
4. 在外生变量上的一个联合概率分布P(U)。

在概率因果模型下,我们就可以定义什么是干预(Intervention)了。比如说刚才提到了一个理想的实验,可以随机强制一个人吸烟或不吸烟,这里的强制就是在干预一个变量。在图模型中,我们强制吸烟变量为1,就可以删去所有指向吸烟变量的有向边,因为其他变量已经不会再影响吸烟变量的值了。如果我们干预了变量X,就记作do(X)。
3. Do-演算与因果之梯
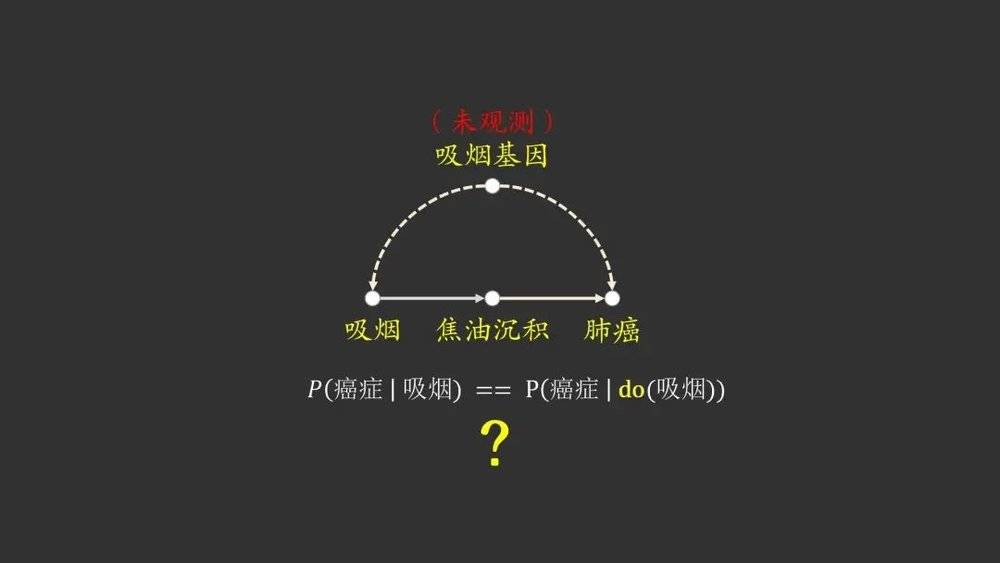
这时我们应该如何去想办法去除吸烟基因的影响,直接计算出随机强制一个人吸烟,其患肺癌的概率是如何的呢?这里所说的强制干预一个变量,就是do-演算框架中的do算子。

为了解决这样的问题,计算出直接干预一个变量后其他变量变化的结果,2011年图灵奖得主Judea Pearl提出了一个do-演算的公理体系,包含三条公理,对观察项和干预项进行转换。这个体系已被证明是完备的。
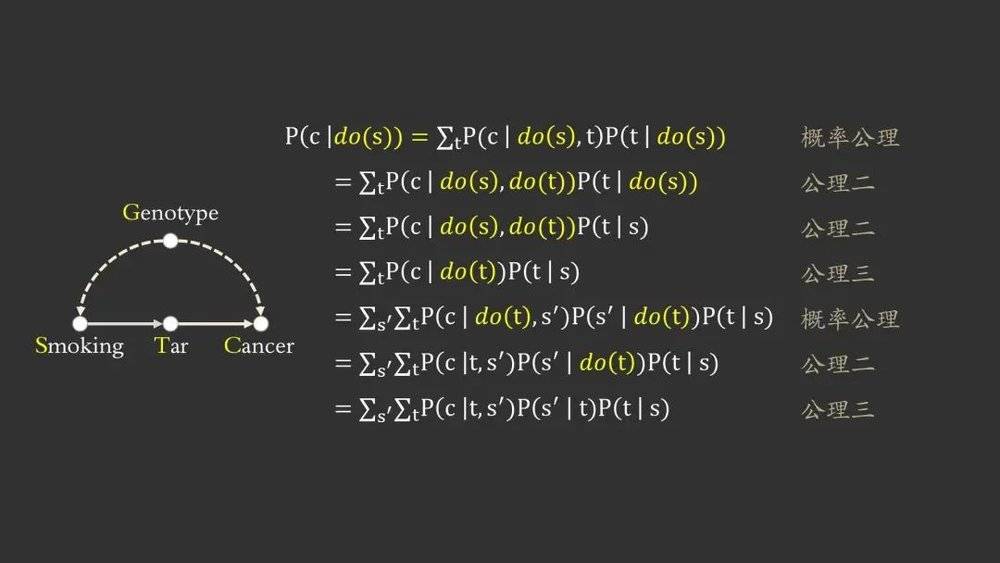
结合do-演算的三条公理,我们就可以将包含 do 算子的表达式 P(c | do(s)) 一步一步地转换成为一个不包含 do 算子的表达式。这样,我们通过对 S、T 和 C 三个变量的观察值进行运算,就可以直接计算出 do(s) 时 c 的分布情况。吸烟致癌的问题就可以得到完美的证明与解答了。可问题是,找出这样一个变换流程是十分困难的,搜索空间巨大,这里就需要 “do-演算 ” 的相关算法进行解决了。
那么do-演算与通常神经网络模型或传统的统计学有什么区别呢?
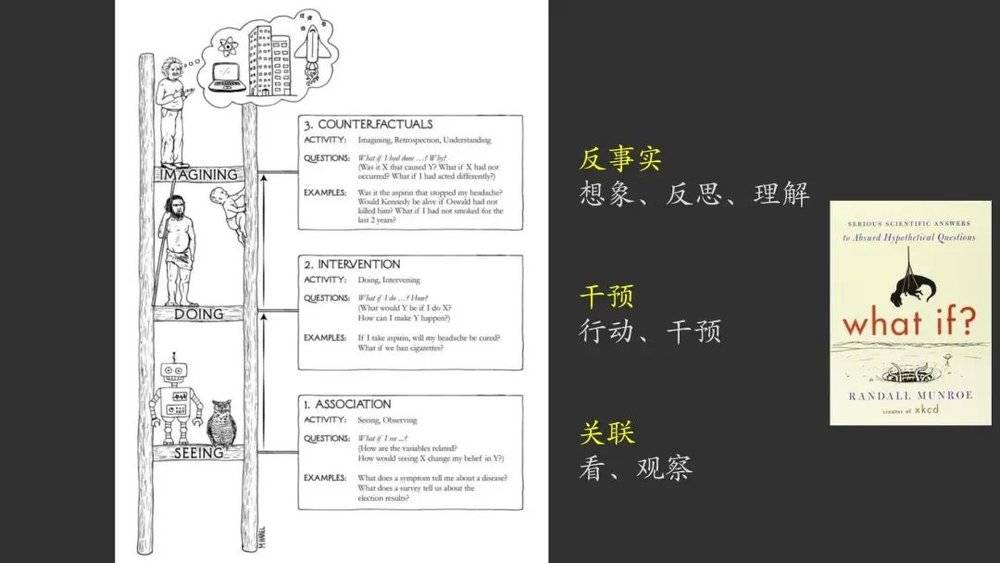
图灵曾经提出了图灵测试来进行一个二元分类——人类和非人类。但Pearl是提出了一个三元分类:
第一层级的梯子上站着的是机器人和动物,能够做的就是基于被动观察来做出预测。Pearl认为,目前为止我们的机器学习进展都还是在这一层级的,无论大家认为它有多么强大。
第二层级的梯子上站着的是原始人类和婴儿,它们学会了有意图地去使用工具,对周遭环境进行干预。
第三个层级上的底子上站着的是有较高智慧的人类,拥有反思的能力,能够在大脑中将真实的世界与虚构的世界进行对比。
在这三个层级上,能够提出和解决的问题是不同的:
在第一个层级上,问题都是基于相关性的,比如:“我的肺部有很多焦油沉积,我未来患肺癌的概率是多少?”
而在第二个层级上,就涉及到了对现实世界的干预,并预测干预结果,比如:“我现在已经吸烟三年了,如果我现在戒烟,我还会患肺癌吗?”
第三个层级上,就是要构建一个虚拟世界,并将虚拟世界与现在进行对比,问题的答案就是对比的结果,比如“如果过去的三年我都没有吸烟,现在我还会患肺癌吗?” Pearl在数学上证明了,这三个层级之间是有着根本的区别的。
因果推理可以在大量的领域得到应用,比如大家都比较关注的复杂系统的漏洞分析,就可以使用 do-演算,减少对实际系统的测试,直接计算出干预的结果。对于医学领域、社会领域、金融领域和强人工智能的开发,都具有决定性的作用,在此我不再赘述。通过手工推导,我们可以解决包含少量变量的因果推理问题,但对于现实中有几十个或者上百个结点的因果图,当前业界还需要一个可以自动化进行因果推理的演算应用框架。
参考文献
[1] J. Pearl, “The Seven Tools of Causal Inference with Reflections on Machine Learning,” Communications of ACM, 62(3): 54-60, March 2019
[2] Bareinboim, E., Correa, J. D., Ibeling, D., & Icard, T. (2020). On Pearl’s hierarchy and the foundations of causal inference. ACM Special Volume in Honor of Judea Pearl (provisional title).
[3] BAREINBOIM E, PEARL J. A general algorithm for deciding transportability of experimental results [J]. Journal of causal Inference, 2013, 1(1):107-134.
[4] GALLES D, PEARL J. Testing identifiability of causal effects [C]//UAI’ 95: Proceedings of the Eleventh Conference on Uncertainty in Artificial Intelligence. San Francisco, CA, USA: Morgan Kaufmann Publishers Inc., 1995: 185–195.
[5] PEARL J. Causal diagrams for empirical research [J]. Biometrika, 1995, 82(4):669-688.
[6] SHPITSER I, PEARL J. Identification of joint interventional distributions in recursive semimarkovian causal models [C]//Proceedings of the National Conference on Artificial Intelligence: volume 21. Menlo Park, CA; Cambridge, MA; London; AAAI Press; MIT Press; 1999, 2006a: 1219.
[7] SHPITSER I, PEARL J. What counterfactuals can be tested [C]//UAI’ 07: Proceedings of the Twenty-Third Conference on Uncertainty in Artificial Intelligence. Arlington, Virginia, USA: AUAI Press, 2007: 352–359.
[8] TIAN J, PEARL J. A general identification condition for causal effects [C]//Eighteenth National Conference on Artificial Intelligence. USA: American Association for Artificial Intelligence, 2002: 567–573.
本文来自微信公众号:集智俱乐部(ID:swarma_org),作者:李奉治 ,编辑:邓一雪

 14:20
14:20









 14:58
14:58
 08:15
08:15
 11:28
11:28
 34:52
34:52
 23:21
23:21
 11:54
11:54
 26:31
26:31
 12:33
12:33
 31:30
31:30



