2026-04-13 08:43

本文来自微信公众号: 叶小钗 ,作者:叶小钗,原文标题:《看不懂 Agent?我让 AI 花一下午写了个 mini-OpenClaw》
小龙虾的火热即将接近尾声,但Agent的大时代才刚拉开序幕,这不Hermes Agent马上就杀了出来!可以预见的是这种Agent系统会越来越多。
所以,我们这批AI工程应用从业者,需要更加系统的了解Agent/OpenClaw的架构,之前我们用整整一个多月带着大家一起阅读了OpenClaw的源码:
《从工程角度为你拆解OpenClaw》
《万字:拆解OpenClaw:从Gateway、Memory、Skills、多Agent到Runtime》
《万字:拆解OpenClaw上下文工程/记忆系统》
《万字:OpenClaw核心机制Skills全解析》
整理了小龙虾的系统架构和工程设计,包括Gateway、Memory、多Agent协作...
但看完后,我觉得它有些复杂:作为一个只想让AI帮我干点杂活的个人用户,这套系统似乎太重了,简直不利于学习!
于是我决定:让AI帮我写一个mini-OpenClaw,全程不动手写一行代码,结果代码是跑起来了,但过程里踩的坑、做的取舍,还是比较有意思。
先看个最终效果:我说了一句
帮我发一篇热点小红书
它就自己去搜了当天热搜、读了新闻详情、写了文案、生成了配图,最后打开浏览器帮我把小红书草稿箱填好了:
这一切是怎么发生的呢?请大家带着前面架构解读的文章和思路,继续往下看:
最终的项目结构
我们以终为始,先看看最终的目录结构:
my_agent/
├──app/#后端(FastAPI)
│├──main.py#入口
│├──api/#API路由(chat、agents、models、tools、skills...)
│├──schemas/#数据模型
│├──services/#业务逻辑(LLM调用、工具执行、记忆检索...)
│├──llm_providers/#LLM适配层(DeepSeek、通义千问、OpenAI兼容)
│├──tools/#内置工具实现
│└──utils/#日志等工具
├──frontend/#前端(Vue 3+Vite)
│└──src/
│├──views/#页面(Chat、Agents、Models、Tools、Skills、Logs、Memory)
│├──stores/#Pinia状态管理
│├──api/#API客户端
│└──components/#组件
├──workspace/#运行时数据
│├──agents/#Agent配置和提示词
│├──skills/#已安装的技能
│├──conversations/#对话历史(JSONL)
│└──*.json#各种配置文件
├──desktop_app.py#桌面应用入口
└──pyproject.toml#项目依赖
以前,想做点程序,要么花钱用别人的平台,要么找程序员朋友帮忙搭一套。现在,你只需要会打字、会描述需求,就能拥有一个属于自己的AI Agent。
让我们一点点继续吧~
技术栈和功能规划
小龙虾的功能很全,多通道设计、会话多车道、定时任务、渠道管理、工具管理、技能管理、记忆管理、权限检查...
想要详细了解的可以看看这篇:万字拆解OpenClaw:从Gateway、Memory、Skills、多Agent到Runtime
不过从架构学习与拆解的角度来说,没必要搞这么复杂。
我的需求其实很简单:一个Web聊天页面,可以日常通过自然语言让Agent干活就行。
如果在这个基础上,能管理Agent、模型、工具、技能、记忆,再加一个模型调用日志的查看界面,方便排查问题就更好了。
把需求描述给AI后,AI给我的建议是Python+React。
后端用Python没啥问题,但前端我熟悉的是Vue,想了想还是让AI改成了Python+Vue,毕竟Vue我还能兜底(只不过结果证明,AI根本不需要我兜底)。
其实真正让我纠结是:自己写还是让AI写。这是个非常大的问题!
如果是生产级应用,我建议暂时还是自己做框架,让AI做辅助,因为其实工作量也不大,不过是从之前的项目里面拷贝、搬运过来罢了...
但如果仅仅是个案例,那就随便咯,不得不说自从用上AI Coding之后,我越来越懒了,只想看AI写代码,下一代可能连“Hello World”是什么这个梗都不知道了...
说干就干,打开Claude Code,把需求一丢:
我现在需要开发一个mini版本的openclaw
后端使用python+FastApi,使用uv进行包管理
前端使用vue
项目采用前后端分离,后端放到目录app中,前端放到目录frontend
不使用数据库,所有数据使用json文件存储保存到workspace目录中
我需要实现以下功能
1、agent管理
2、工具管理
3、技能管理
4、模型管理
5、聊天窗口和指定的agent聊天,没有指定就使用默认的agent
你需要先给我指定一个详细的开发计划,并且输出到文档中
需要给出一个开发进度表,每完成一个功能,就标记状态为完成
AI很快就给出了开发计划,技术栈是这些:
| 层级 | 技术选择 |
|---|---|
| 后端 | Python 3.10+,FastAPI,uv(包管理),Pydantic |
| 前端 | Vue 3,Vite,Pinia(状态管理),Axios,TailwindCSS |
| 数据存储 | JSON文件(位于workspace/目录) |
| 开发工具 | uv,Node.js 18+,Git |
计划和我想要的差不多,那就开干。整体架构长这样:

PS:从这里也可以看出我们与一般小白的不同,我们是具备对AI的评价能力的,包括架构和具体实现细节的各种评价,而这个评价在复杂项目里面就很重要了
一步一步,从零搭建
开发过程按AI给的任务列表逐个推进,每完成一个功能就标记状态,然后开一个新会话继续下一个:
@开发计划文档.md现在需要继续开发任务编号为3的功能模块Agent管理,只需要开发这个模块,完成后修改状态。
这里为什么要开一个新会话?主要是上下文限制。这些功能模块比较独立,单独开一个新会话,AI没有历史消息的负担,可以更好地干活。
就这样一个个推进,很快完成了第一版。界面不太好看,用技能frontend-design美化了一次:
使用frontend-design帮我优化界面,颜色配置不要太鲜艳了,需要谈一点
最后的结果如下:

功能看着都有了,但还没有实际测试过。接下来逐个验证,不符合预期的就通过自然语言描述让AI改。
模型管理
接入了DeepSeek、通义千问这两种国产模型,也支持任何OpenAI兼容接口。
API Key单独存在.env文件里,不在配置文件里明文暴露,还做了个"连接测试"功能,配好模型点一下就知道能不能用,这个很实用:

每个模型的新增、修改、删除都需要手动测试。比如测试时就碰到了编辑数据无法保存的问题,直接告诉AI:
模型管理,在编辑页面。修改之后保存不生效

Agent管理
每个Agent有自己的system prompt和知识库,用Markdown文件存(agent.md和knowledge.md),可以直接在界面上编辑。
Agent可以关联指定的模型、工具和技能,配一个默认Agent不能删:

然后就是工具管理模块了:
工具管理
一开始只有默认的文件读写功能,我需要先想好要哪些工具,然后让AI去开发工具库。
根据历史经验,最终实现了6大类共12个工具:文件读写、系统命令、代码执行、Excel操作、文生图、浏览器操作(browser use)。
后面会详细展开。

这些工具通过自然语言描述就能让AI生成,并且让它自己测试,没问题才算完成。
需要特别说一嘴的是:浏览器操作工具最折腾,AI最初给的版本根本用不起来!
我跟他叽歪了半天,它也干了半天,效果还是不理想,我也不想再折腾,直接打开Openclaw的源码,让AI分析它的浏览器操作是怎么设计和实现的,生成一份文档,然后再把文档丢给AI,让它在我的项目里实现一个一样的......
PS:从这里大家应该可以更清晰Claude Code泄露的意义在哪了吧
核心思路是用Playwright做浏览器自动化,但没用传统的CSS选择器方式,而是基于ARIA无障碍树。
简单来说:AI先拿到页面的无障碍树,每个可交互元素都有一个ref ID,然后通过ref ID来操作元素。这种方式比CSS选择器稳定一些,页面改版也不怕。
无论是浏览器操作、还是电脑操作,都是Agent最核心、最原子的能力,只是他们需要优化的点还很多,具体想更多了解的可以看看这篇文章:
《Browser Use到底能不能用?》
最后浏览器用Chrome的CDP协议独立启动,应用退出了浏览器还在,登录状态一直保持,登录一次,以后就不用再登了。
接下来是Agent第二核心,技能包模块了:
Skills管理
这块支持扫描本地目录发现新技能、在线编辑,还能安装OpenClaw的技能,共享其生态:

技能这东西按需安装就行,可以去OpenClaw的技能生态中下载,通过导入ZIP文件完成安装,也可以直接让AI帮我们创建:
我现在需要一个技能,用来读取pdf和word文档的内容

其中技能的编辑页面,AI最开始给出来的很复杂,它只读取了Skill.md的名称和描述,其他的内容都没有显示出来,其实我想要的是整个技能的目录按照树形结构加载,技能的内容我也可以修改,于是让AI修改
技能编辑的时候,目前只能编辑名称和描述
我希望把技能的目录列出来,左边是树形结构,右边是内容
文件内容都可以编辑保存

到这里基本工作就做得差不多了,可以进入聊天模块的设计了:
聊天功能
聊天是整个系统的核心,也是花时间最多的地方、最折腾的部分:

基础功能验证完成后,打开了聊天界面,给咱们的Agent发了一条你好。
等了一会儿,它告诉我它是DeepSeek,而且也不是流式输出;我再问它有什么技能和工具,它说啥都没有,只能聊天......
所以,我搞了那么多,白做了是吧?这就是第一版的真实水平:一个裸奔的聊天框。
做程序其实就一个思路,发现问题解决问题就好,没有问题就不需要解决。
所以针对这里的前端没有实现流式输出,技能和工具也没有组装到提示词中,告诉AI就好:
目前聊天窗口中,没有使用流式输出,你需要添加这个功能。
另外提示词没有组装工具和技能给到大模型,这个也需要加上。
AI修改完成后,流式输出有了,技能也能用了:

后续还遇到了不少问题,都是发现一个解决一个:
模型已经说明要调用工具,但是系统没有去执行
模型有思考能力,但聊天界面没有支持思维链的输出
工具和技能的执行输入和输出没有显示到界面上
图片生成后,没有在界面上预览出来
会话记录没有保存
没有将会话记录加入到上下文中
生成的文件、Excel不好查看
上述都是小Case,而聊天界面差点让我崩溃。这个界面太复杂了:
思考模型要输出思维链,非思考模型没有,而且思维链和其他问答的配色还不一样;
工具执行要显示,技能执行也要显示;
技能执行的中间日志要实时输出;
图片生成需要预览
...
所有这些功能夹在一起,页面就非常复杂。这也符合我们历史的开发经验,我们有年限百万的同事,一年就只需要折腾一个界面,反复打磨就好,因为真实情况也确实有很多问题。
这里的真实情况是:前一秒刚把技能日志输出改好,后一秒工具执行结果显示又出问题,那两天来来回回改了好几轮,才勉强把这个页面的逻辑理顺。
所以这里有一个小建议:如果某部分功能改到满意了,一定要提交保存。这也是我们之前传授AI Coding经验时候最常见的提示:
《万字:普通人学AI Coding》
不然AI下次改其他问题的时候,可能把之前好好的部分也给改掉了,我在这里就遇到了两次改乱的情况。
PS:虽然给出了很多建议,但我们其实经常自己也图方便不遵守
最终的界面布局:左边是会话列表,中间是聊天区域,右边是聊天过程中产生的临时文件和最终产物(图片、PPT、Excel、文档等)。
中间聊天区域承载的内容较多:
思维链的输出
工具的执行和输出
图片预览
技能的执行和输出
文件上传
工具调用方面,AI在聊天过程中可以自主调用工具和技能,工具执行结果返回给AI继续推理,最多支持50轮循环。
这里我们实现的Agent采用比较经典的ReAct模式来进行推理。
ReAct的运行机制可以概括为一个经典的循环:Thought(思考)→Action(行动)→Observation(观察)。
这个循环不断迭代,直到Agent获得足够的信息来回答用户的问题,关于Agent ReAct模块的基础知识不熟悉的同学,可以看这篇文章:
《万字:Agent概述》
在具体调试上我们需要观察llm的日志来查看系统有没有按照这个模式来执行

对话历史选了JSONL格式存储,每条消息一行,追加写入。每个会话一个文件,每个会话还有一个文件夹,用来存放AI生成的文件和中间结果,保存到workspace目录下。
在我们的工作目录workspace中保存了所有会话的记录,我们在和AI对话之后,需要去检查这个目录里面的数据是否正常:

至此,其实主体功能就已经差不不多了,整个Agent的核心机制都够了,如果目的仅仅是学习,便可以到此为止;
但如果你想让他看上去稍微聪明点,那就需要上记忆系统了,这也是比较难的部分,我们这里也只实现了皮毛:
记忆系统
除了以上基础模块,我还给每个Agent加了一个记忆功能。
记忆系统很重要,否则每次开新会话,Agent都是从零开始,昨天跟它说的话它全忘了。
比如我跟它说过"写文案不要用emoji",下次它照样给你加一堆表情,这也是我们前面说他显得很蠢的原因。
其实这里模型并不蠢,因为模型API,是一套标准一次性输入输出,他又没有记忆,记忆是我们需要做的工程控制,于是让AI帮我加了个记忆系统。
每个Agent有一个MEMORY.md文件,专门记重要的事。对话聊到一定程度,系统会自动触发一次记忆保存。
让AI自己判断哪些信息值得记住,写到文件里,下次开新会话,它会先翻翻自己的小本子,把之前的偏好和上下文捡回来。
检索这块也做了点功夫,越早的记忆权重越低,免得AI老拿三个月前随口说的一句话当圣旨,重复的内容也会自动去重。
还是那句话,记忆系统的复杂度很高,就算是OpenClaw的记忆机制都经常被人诟病,记忆机制的背后又是知识库,这块挺复杂的,大家有兴趣先看看文章,我们这里不展开:
《万字:拆解OpenClaw上下文工程/记忆系统》
至此,一个用于学习的Mini-OpenClaw就真的差不多了,在这个基础下便可以继续做些体验上的优化:
打包成桌面应用
我其实不需要打包成桌面应用,我直接在web上就可以让AI干活了。
但有个朋友也想用,他不是技术人员,电脑上没有Python和npm,他需要的是一个双击就能用的程序。
于是让AI帮忙写了个打包脚本。
用PyInstaller+pywebview把整个应用打包成macOS的.app,双击就能用,不用装Python、不用装Node.js、不用开终端。
PS:Windows我就没管了,毕竟这年头正经人谁还用那玩意
额,但要说一句的是,这一步还是踩了不少坑...
开发模式和打包模式的资源路径完全不同,技能脚本需要独立虚拟环境运行,Chrome浏览器的启动路径也不一样。
pywebview还有连接超时的问题,流式输出会断,折腾了好久,最后加了个心跳包,每15秒发一个keepalive才算搞定...
PS:还是那句话,AI Coding确实可以解决很多小问题,但传统程序员最核心的技能其实是死命折腾,这点不具备也做不好程序
至此,整个系统就真的做完了,于是乎,我们做下扩展,聊聊什么是生态问题:
系统里有哪些工具
工具是Agent的基础能力,系统内置了12个工具,每个都注册在工具注册器里,AI在聊天时可以自主调用:
| 工具 | 说明 |
|---|---|
| file_read/file_write | 文件读写,AI可以读取和创建文件 |
| command_execute | Shell命令执行,可以跑任意终端命令 |
| code_execute | Python代码执行,用来跑代码片段 |
| web_search | DuckDuckGo网页搜索,用来搜索信息 |
| web_read | 网页内容提取,三级策略:先httpx直连,不行用trafilatura,还不行上Playwright无头浏览器 |
| browser_use | 浏览器自动化,支持22种操作(点击、输入、截图、滚动、标签页管理等),基于ARIA无障碍树 |
| image_generate | AI图片生成,调用配置好的图片模型 |
| excel_read/excel_write/excel_sheets | Excel读写和查询,用openpyxl实现 |
| memory_search/memory_get/memory_save | Agent记忆管理,搜索、读取、保存记忆 |
上述工具库就是整个系统基本能力的核心,也是需要不停做扩展的地方。
举个例子,如果你接下来需要操作多维表格、或者各种内部系统,那么就需要自己扩展工具
这些工具里面,不得不提一下code_execute。这个代码执行工具有点让人又爱又恨,我使用他其实就只是想拿来做个兜底,但真实情况是很多时候明明有其他工具和技能可以用,AI就非要自己写代码来用这个工具执行。
AI是真的很喜欢写代码!但它自己又一次性写不好,折腾半天,最后还是得靠技能来完成任务。所以如果没有特殊需求,这个工具我都不给Agent用了...
系统里有哪些技能
工具是底层能力,技能是上层编排,这两个是Agent生态扩展的核心,Skills的本质是SOP,工具是这套SOP能不能被执行的根本
我们这里,系统支持两种技能类型:
Prompt型技能:只有一个SKILL.md文件,本质是一套提示词模板。AI读到提示词后,自己决定怎么调用工具完成任务,好处是简单灵活,不依赖任何外部脚本。
Script型技能:除了SKILL.md,还有scripts/main.py,会以子进程方式执行。脚本的标准输出会实时流式回传到聊天界面,用户能看到执行过程。每个技能运行在独立的Python虚拟环境里,不会影响主应用。
技能安装很方便,可以直接上传ZIP包(GitHub下载的压缩包直接能用),也可以扫描本地目录自动发现新技能,还能在界面上在线编辑。
目前系统里安装了这些技能:
hot-news-top10—热点新闻搜索。用DuckDuckGo搜索当日热点,自动聚类打分输出TOP10。可以传关键词搜特定领域,也可以不传搜通用热点。这个技能是很多复合技能的基础组件。
douyin-summary—抖音视频总结。输入抖音链接,自动提取视频内容并总结。
douyin-comment—抖音自动评论,通过浏览器自动化技术,将指定的评论发布,或者结合douyin-summary自动生成评论内容发布
xhs-hot-publisher—小红书热点图文自动发布。这是一个多步骤复合技能:先搜热点→用户选题→深度采集内容→生成配图→撰写文案→浏览器自动发布到小红书草稿箱。
xiaohongshu-publish—小红书发布工具。配合xhs-hot-publisher使用,通过浏览器自动化把图文发布为小红书草稿。
create-pptx—PPT生成。基于python-pptx库,自带商务和教育两套模板,能生成时间线、图表、多页幻灯片,还考虑了WPS兼容性。
file-reader—文档读取。支持PDF和Word文档的文本提取,用pymupdf和python-docx实现。
skill-creator—技能生成器。用来自动创建新技能的技能,输入需求就能生成SKILL.md和脚本模板,自动注册到系统。
如果觉得不沟通,首先可以从网上下载,但从学习的角度,我是建议各位自己简单写一写,最后我们来看看演示效果吧:
案例演示
光说功能太抽象了,下面用几个实际例子展示Agent是怎么工作的。
案例1:搜索热点新闻
这是最基础的用法,一个技能就能搞定。
用户:今日有哪些热点事件
AI:我来搜索今日的热点事件。我可以使用hot-news-top10技能来获取全网热点新闻。
这个技能会搜索热点新闻并生成TOP10选题,包含事件描述、核心角度和标题等信息。
让我调用这个技能。
整个过程很快就完成了。用户只需要说一句话,AI自己决定调用哪个技能来实现需求。

案例2:抖音视频总结
这个稍微复杂一点,涉及链接识别和内容提取。
用户:https://www.douyin.com/video/7625983892776400448?modeFrom=帮我看看这个视频说了什么
AI:用户提供了一个抖音视频链接,要求我看看这个视频说了什么。
我应该使用抖音视频总结助手(skill_douyin_summary)来处理这个请求。
AI先识别链接类型,然后调用对应的技能脚本,脚本输出实时流式显示,最后AI再对内容做一次总结整理。


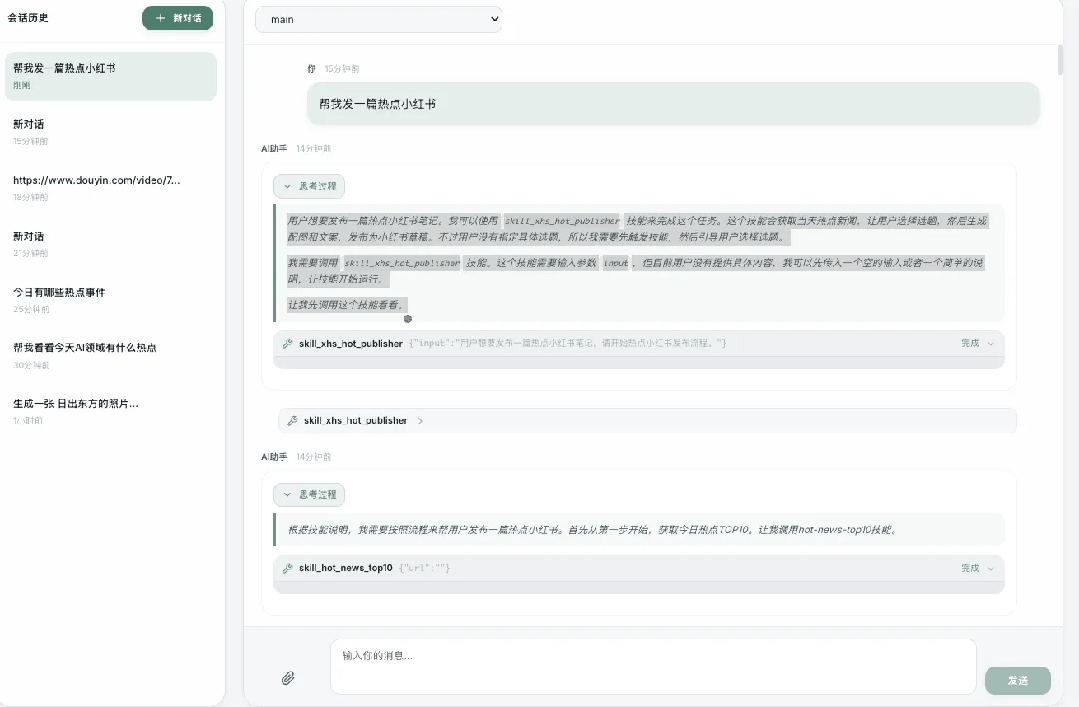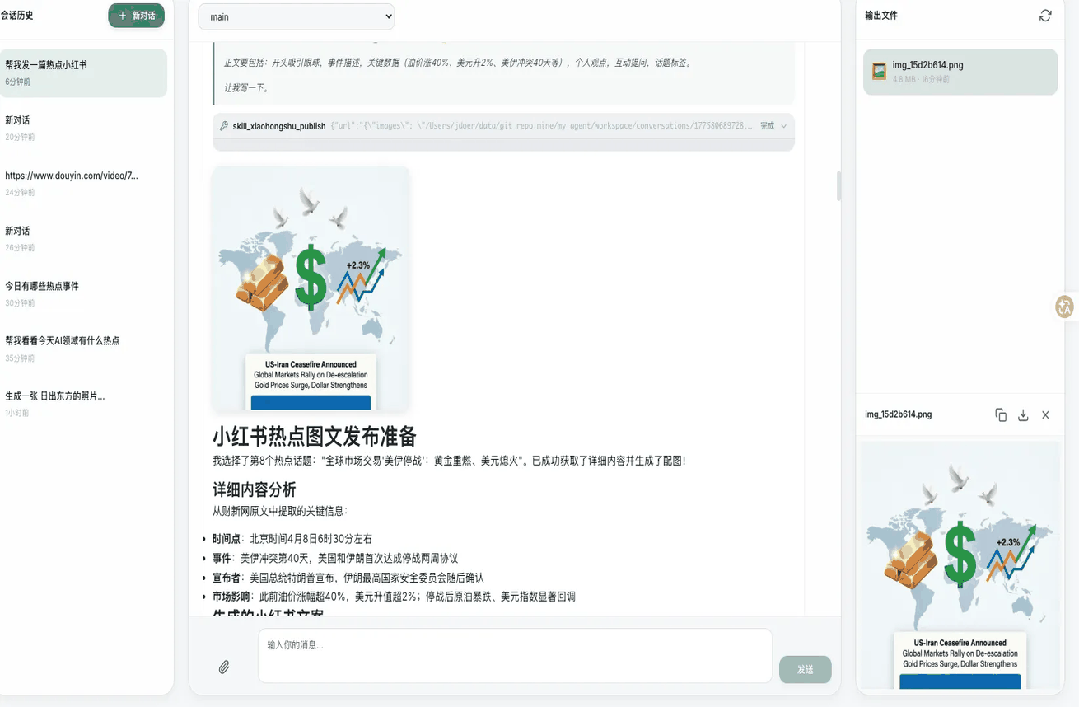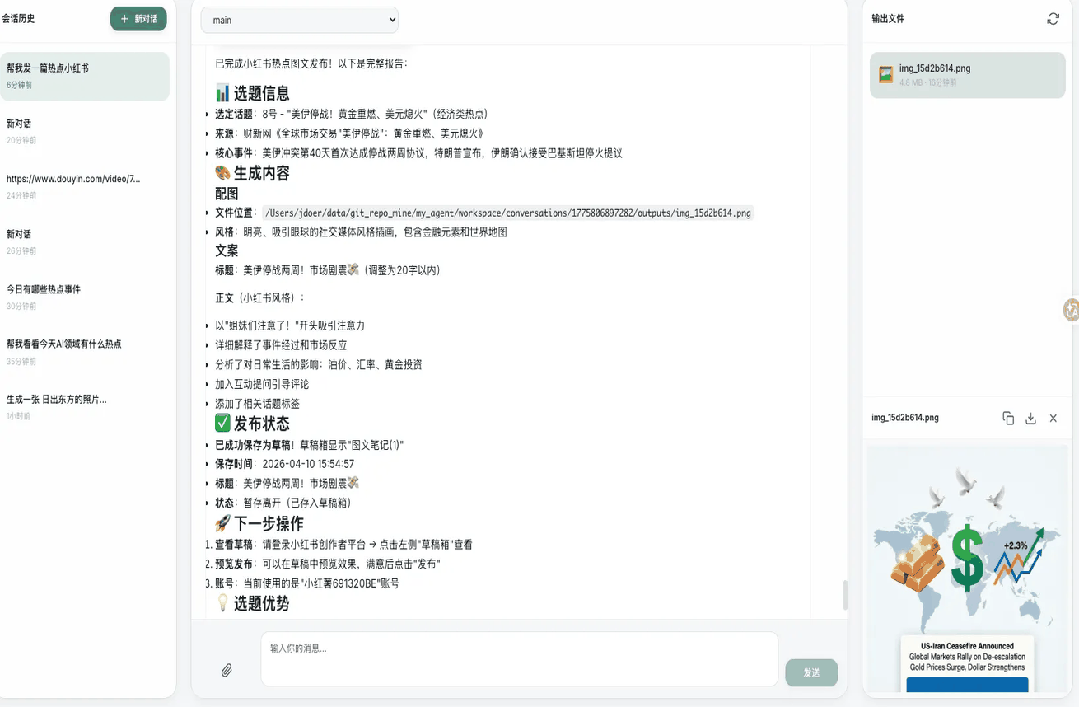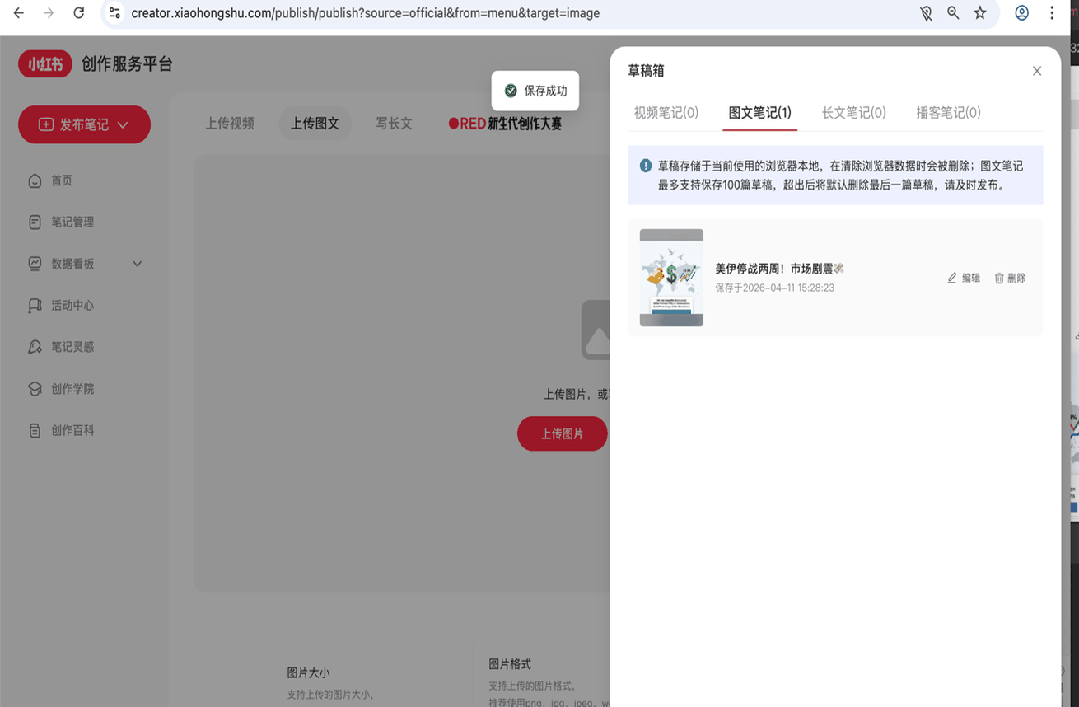
案例3:小红书热点图文自动发布
这是最能体现Agent能力的案例:一个需求串联了5个步骤,跨越搜索、网页读取、图片生成、文案创作、浏览器自动化发布等多个能力。
用户:帮我发一篇热点小红书
AI直接使用了技能skill_xhs_hot_publisher:
用户想要发布一篇热点小红书笔记。
我可以使用skill_xhs_hot_publisher技能来完成这个任务。
这个技能会获取当天热点新闻,让用户选择选题,然后生成配图和文案,发布为小红书草稿。

后续调用了技能hot_news_top10获取热点新闻,这里需要用户手动确认一条热点新闻,技能里也可以选择自动确认,跳过人工环节。

确认热点新闻后,AI会调用web_read工具获取详细内容,为生图和文案创作提供素材,最后调用xiaohongshu_publish技能完成发布。

发布结果:

内容暂存在小红书的草稿里,需要手动确认后再发布。目前内容还是Markdown格式的纯文本,样式还需继续优化。

整个流程中,用户看上去只做了两件事:说了一句话、选了一个选项。
剩下的搜索、采集、生成图片、写文案、发布,全部由Agent自主完成。
但如果你打开执行日志,就会知道Skills和工具才是根本了,本质是Workflow换了个承载工具。
结语
好了,之前写架构解读相关文章,总有朋友说读不懂,我今天TM一个字代码都没写,总不可能读不懂了吧?
回头看整个开发过程,有三点我相信大家也会影响深刻:
一、评价能力很重要
可以让AI写代码,但你要懂架构。
整个项目绝大部分代码是AI(Claude Code)写的,但技术选型、模块划分这些关键决策是我做的。
系统架构设计、框架搭建、前端页面布局等则全部由AI完成。
你和AI的关系更像产品经理和程序员,你负责想清楚要什么,它负责实现。
但你有没有对他工作的评价能力,这就变得很重要了。
二、颗粒度对齐!
有些时候,这些黑话还是挺有意思的,比如:怎么确认AI写的代码是你想要的。那就不得颗粒度对齐了吗?
界面上的功能好验证,自己操作看看预期是否一致就行。但后台逻辑呢?不懂技术的话,看不懂代码,怎么确认AI写的功能和自己设计的是一致的?
我总结了几个办法,这些颗粒度要对齐:
让AI对照业务需求做自查
让AI输出关键步骤的日志
用文件或简单数据库存储数据,直接查看
让AI生成可读的测试报告
准备一些测试例子,看看输出是否符合预期
三、生态才是核心
我们这里是做课件,帮助大家做学习的,但生态的威力相信大家也能有所感受,暂时来说:
技能系统是最有价值的设计
工具是静态的、通用的、你看不到的;技能是动态的、可扩展的,用户在实际使用的。
从"帮我搜个新闻"到"自动发一篇小红书",技能把零散的工具能力编排成了有意义的自动化流程。
一个好的技能系统让Agent的能力可以无限扩展。
一个在前、一个在后,这两个生态怎么配合,就算真的做Agent平台的公司需要思考的了。
好了,今天的文章内容就到这了,如果你这都不点赞,那我也真的无话可说了...
本内容来源于网络 原文链接,观点仅代表作者本人,不代表虎嗅立场。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。
如涉及版权问题请联系 hezuo@huxiu.com,我们将及时核实并处理。