2023-05-09 15:20


扫码打开虎嗅APP

本文来自微信公众号:机器之心 (ID:almosthuman2014),编辑:杜伟、陈萍,原文标题:《图与代码不一致,Transformer论文被发现错误,网友:早该被指出1000次》,题图来自:《华尔街之狼》
2017 年,谷歌大脑团队在其论文《Attention Is All You Need》中创造性地提出 Transformer 这一架构,自此这一研究一路开挂,成为当今 NLP 领域最受欢迎的模型之一,被广泛应用于各种语言任务,并取得了许多 SOTA 结果。
不仅如此,在 NLP 领域一路领先的 Transformer,迅速席卷计算机视觉(CV)、语音识别等领域,在图像分类、目标检测、语音识别等任务上取得良好的效果。

论文地址:https://arxiv.org/pdf/1706.03762.pdf
从推出至今,Transformer 已经成为众多模型的核心模块,比如大家熟悉的 BERT、T5 等都有 Transformer 的身影。就连近段时间爆火的 ChatGPT 也依赖 Transformer,而后者早已被谷歌申请了专利。

图源:https://patentimages.storage.googleapis.com/05/e8/f1/cd8eed389b7687/US10452978.pdf
此外 OpenAI 发布的系列模型 GPT(Generative Pre-trained Transformer),名字中带有 Transformer,可见 Transformer 是 GPT 系列模型的核心。
与此同时,最近 OpenAI 联合创始人 Ilya Stutskever 在谈到 Transformer 时表示,当 Transformer 刚发布之初,实际上是论文放出来的第二天,他们就迫不及待将以前的研究切换到 Transformer ,后续才有了 GPT。可见 Transformer 的重要性不言而喻。
6 年时间,基于 Transformer 构建的模型不断发展壮大。然而现在,有人发现了 Transformer 原始论文中的一处错误。
Transformer 架构图与代码“不一致”
发现错误的是一位知名机器学习与 AI 研究者、初创公司 Lightning AI 的首席 AI 教育家 Sebastian Raschka。他指出,原始 Transformer 论文中的架构图有误,将层归一化(LN)放置在了残差块之间,而这与代码不一致。
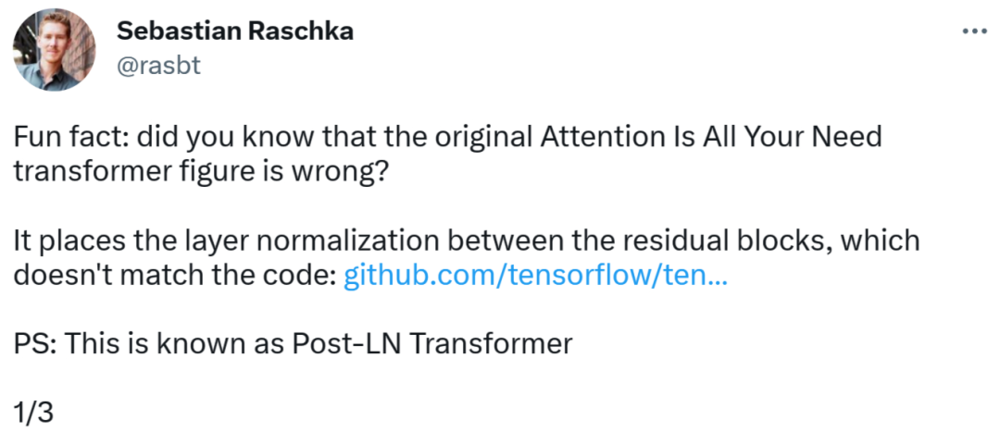
Transformer 架构图如下左,图右为 Post-LN Transformer 层(出自论文《On Layer Normalization in the Transformer Architecture》[1])。

不一致的代码部分如下,其中 82 行写了执行顺序“layer_postprocess_sequence="dan"”,表示后处理依次执行 dropout、residual_add 和 layer_norm。如果上图左中的 add&norm 理解为:add 在 norm 上面,即先 norm 再 add,那确实代码和图不一致。

代码地址:https://github.com/tensorflow/tensor2tensor/commit/f5c9b17e617ea9179b7d84d36b1e8162cb369f25#diff-76e2b94ef16871bdbf46bf04dfe7f1477bafb884748f08197c9cf1b10a4dd78e
接下来,Sebastian 又表示,论文《On Layer Normalization in the Transformer Architecture》认为 Pre-LN 表现更好,能够解决梯度问题。这是很多或者大多数架构在实践中所采用的,但它可能导致表示崩溃。
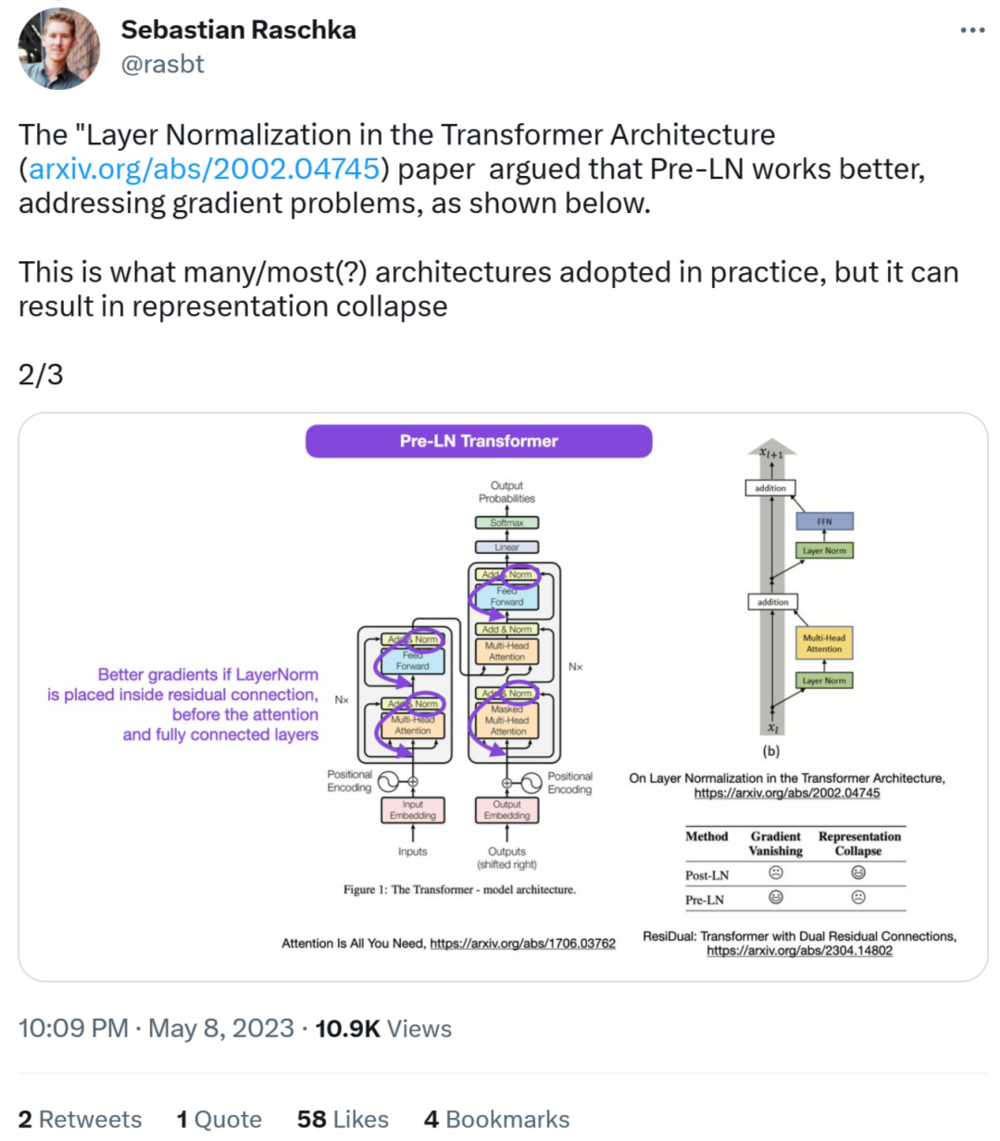
因此,虽然关于 Post-LN 或 Pre-LN 的争论仍在继续,但另一篇论文结合了这两点,即《ResiDual: Transformer with Dual Residual Connections》[2]。

对于 Sebastian 的这一发现,有人认为,我们经常会遇到与代码或结果不一致的论文。大多数是无心之过,但有时令人感到奇怪。考虑到 Transformer 论文的流行程度,这个不一致的问题早就应该被提及 1000 次。
Sebastian 回答称,公平地讲,“最最原始”的代码确实与架构图一致,但 2017 年提交的代码版本进行了修改,同时没有更新架构图。所以,这实在令人困惑。

正如一位网友所说:“读代码最糟糕的是,你会经常发现这样的小变化,而你不知道是有意还是无意。你甚至无法测试它,因为你没有足够的算力来训练模型。”
不知谷歌之后是否会更新代码还是架构图?
参考链接:
论文[1]:https://arxiv.org/pdf/2002.04745.pdf
论文[2]https://arxiv.org/pdf/2304.14802.pdf
本文来自微信公众号:机器之心 (ID:almosthuman2014),编辑:杜伟、陈萍

 03:40
03:40









 14:58
14:58
 12:11
12:11
 09:57
09:57
 32:32
32:32
 07:53
07:53
 20:24
20:24
 34:59
34:59
 20:47
20:47
 03:11
03:11



