2020-05-26 19:04


扫码打开虎嗅APP

本文来自微信公众号:芯东西(ID:aichip001),作者:心缘,头图来自unsplash
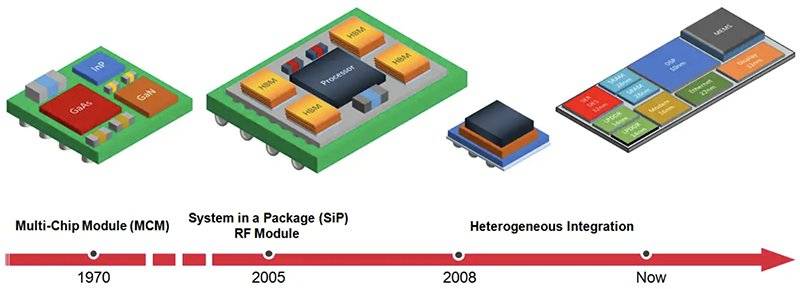
10nm、7nm、5nm……随着芯片制程节点越来越先进,研发生产成本持续走高,而良率日益下降,物理瓶颈正拖累摩尔定律的脚步。
像搭乐高积木一样的小芯片(Chiplet)正成为AMD、英特尔、台积电、Marvell、Cadence等芯片巨头为摩尔定律续命的共同选择之一。
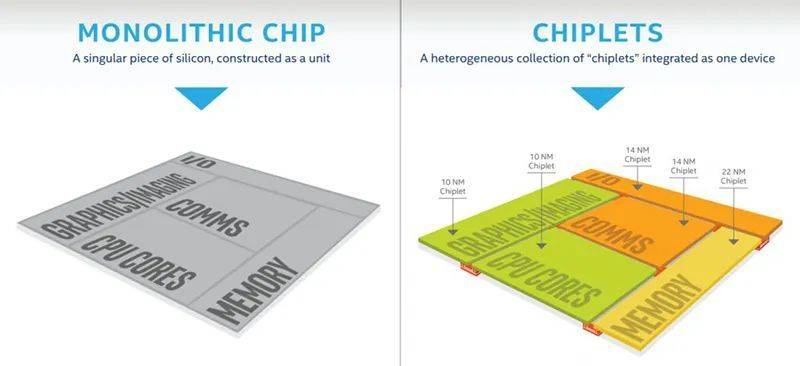
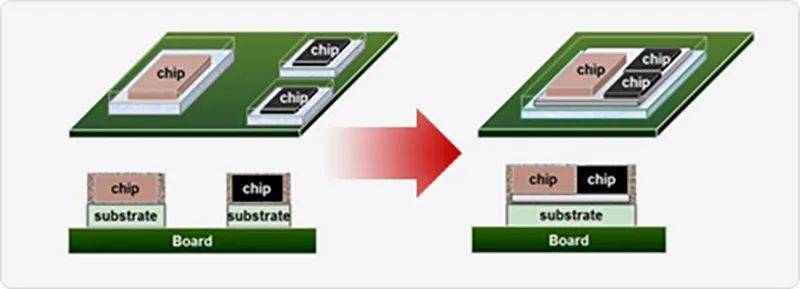
以前芯片由多个IP核心集成后统一封装成单片芯片,而小芯片方法可将来自不同公司设计和封装的小芯片组合在一起,从而构建更为高效和经济的芯片系统。
这种新型设计方法不仅能大大简化芯片设计复杂度,还能有效降低设计和生产成本。
知名市场研究机构Omdia预测,小芯片将在2024年全球市场规模扩大到58亿美元,较2018年的6.45亿美元增长9倍。而长远来看,2035年小芯片市场规模有望增至570亿美元。
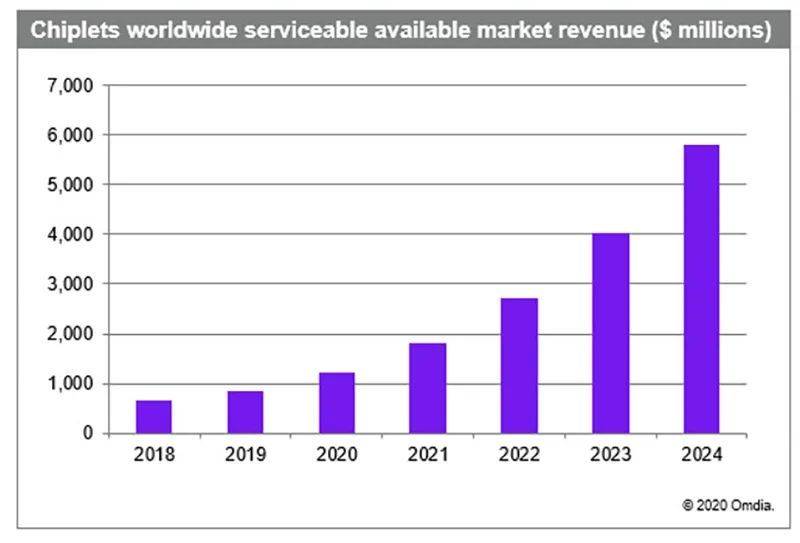
2018-2024年全球小芯片市场收入(来源:Omdia)
围绕小芯片的新战事,正在将芯片性能进化引向更具经济效益的未来。
一、续命摩尔定律!小芯片时代来了
55年前,被推崇为芯片界“圣经”的摩尔定律预言:当价格不变时,集成电路上可容纳的晶体管数量每隔18~24个月会增加一倍,性能也随之提升一倍。
当年摩尔定律的出现设定了极为关键的技术发展节奏基准,催化了科技市场欣欣向荣,为整个IT行业带来了难以估量的经济价值。
使用先进节点的好处很多,晶体管密度更大、占用空间更少、性能更高、功率更低,但挑战也越来越难以克服。
极小尺寸下,芯片物理瓶颈越来越难以克服。尤其在近几年,先进节点走向10nm、7nm、5nm,问题就不再只是物理障碍了,节点越进化,微缩成本越高,能扛住经济负担的设计公司越来越少。
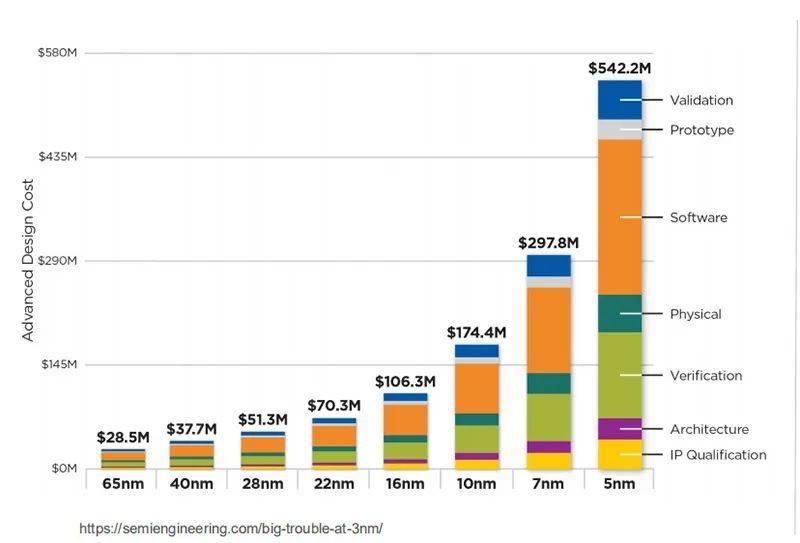
随着制程节点进化,芯片成本快速增长
根据公开报道,28nm节点设计成本约为5000万美元,而到5nm节点,设计总成本已经飙高到逾5亿美元,相当于逾35亿人民币。
而守住摩尔定律,关乎利润最大化,如果研发和生产成本降不下来,那么对于芯片巨头和初创公司来说都将是糟糕的经济负担。
幸运的是,每当摩尔定律被唱衰将走到尽头,总会激发出科学家和工程师们创新构想,提出力挽狂澜的突破性技术,将看似走向终结的摩尔定律一再推向远方。
基于小芯片的模块化设计,正是其中解决成本问题的一个极为关键的构想。
二、小芯片的三大价值:开发快、成本低、功能多
当前芯片设计模式常从不同IP供应商购买软核IP或硬核IP,再结合自研模块集合成一个片上系统(SoC),然后以某个制造工艺节点生产出芯片。
而小芯片通过先进封装技术,能将多种不同架构、不同工艺节点、甚至来自不同代工厂的专用硅块或IP块集成在一起,可以跳过流片,快速定制出一个能满足多种功能需求的超级芯片产品。
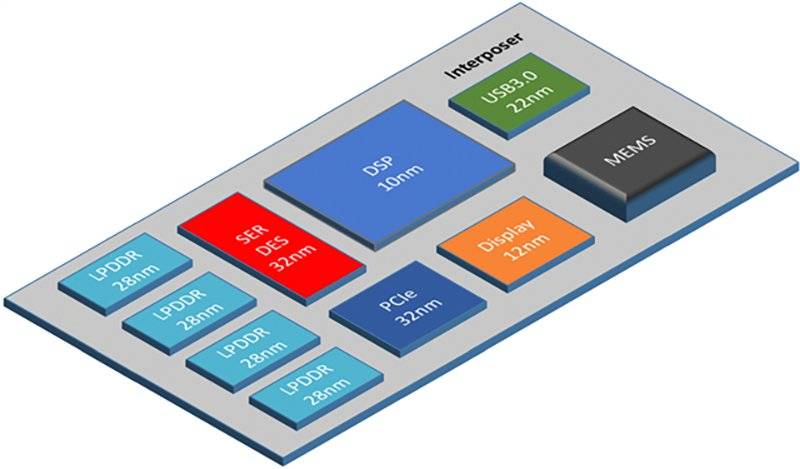
由中介层上多个小芯片组成的小芯片系统(来源:Cadence)
相比单片芯片,小芯片带来的好处是多重的。
首先,小芯片开发速度更快。
在服务器等计算系统中,电源和性能由CPU核心和缓存支配。通过将内存与I/O接口组合到一个单片I/O芯片上,可减少内存与I/O间的瓶颈延迟,进而帮助提高性能。
其次,小芯片的研发成本更低。
因为小芯片是由不同的芯片模块组合而成,设计者可在特定设计部分选用最先进的技术,在其他部分选用更成熟、廉价的技术,从而节省整体成本。
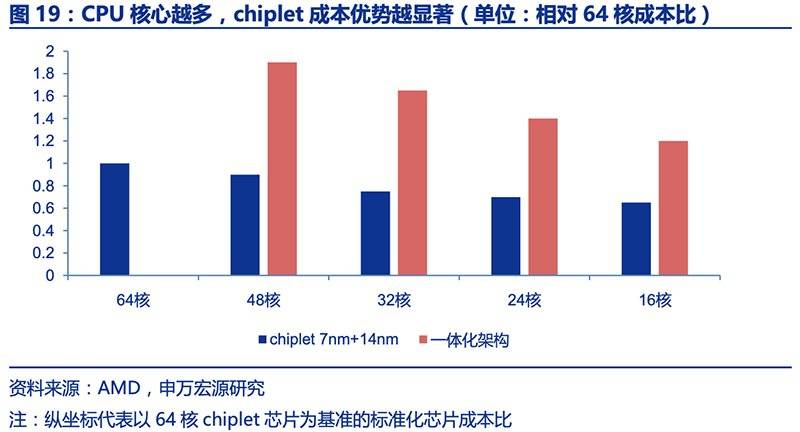
例如,AMD第二代EPYC服务器处理器Ryzen采用小芯片设计,将更先进的台积电7nm工艺制造的CPU模块与更成熟的格罗方德12/14nm工艺制造的I/O模块组合,7nm可满足高算力的需求,12/14nm则降低了制造成本。
这带来的好处是,7nm制程部分的芯片面积大幅缩减,而采用更成熟制程的I/O模块有助于整体良率的提升,进一步降低晶圆代工成本。综合来看,CPU核心越多,小芯片组合的成本优势越明显。
最后,小芯片能灵活满足不同功能需求。
一方面,小芯片方案具备良好的可扩展性。例如构建了一个基本die后,可能只用一个die可应用于笔记本电脑,两个可应用于台式机,四个可应用于服务器。
另一方面,小芯片可以充当异构处理器,将GPU、安全引擎、AI加速器、物联网控制器等不同处理元素按任意数量组合在一起,为各类应用需求提供更丰富的加速选择。
随着小芯片的优势逐渐显露,它正被微处理器、SoC、GPU和可编程逻辑设备(PLD)等更先进和高度集成的半导体设备采用。
根据研究机构Omida统计,微处理器是小芯片最大的细分市场,支持小芯片的微处理器市场份额预计从2018年的4.52亿美元增长到2024年的24亿美元。
同时,计算领域将成为小芯片的主要应用市场,今年有望占据小芯片总收入的96%。
三、六年跋涉,从各自为营到走向标准化
芯片巨头们对风向的变化尤为警觉,没有谁想从神坛上跌落。在守着最先进设计和制造技术的同时,他们必须为自己提前探好新的可行之径。
也正因为如此,英特尔、AMD等芯片领军企业不仅成为最早的小芯片采用者和倡导者,也是推动小芯片标准化工作的核心贡献者。
早在2014年,华为海思与台积电曾合作秀出一款采用台积电CoWoS技术的网络芯片,将16nm 32核Arm Cortex-A57与28nm逻辑和I/O芯片组合在一起,在相同功耗下速度较28nm HPM提升40%。
台积电CoWoS示例
2016年,Marvell和Kandou Bus宣布一项协议,Marvell采用了Kandou Glasswing IP作为芯片到芯片的接口,将多个芯片相连接。
美国国防部高级研究计划局(DAPRA)则在2017年8月启动“通用异构集成及IP复用策略(CHIPS)”项目,这是DAPRA总投资15亿美元的“电子复兴计划(ERI)”中的一部分,意在促成一个兼容、模块化、可重复利用的小芯片生态系统。
这些小芯片能将各种类型的第三方芯片像堆积木一样快速混搭成一个系统,实现数据存储、信号处理、数据处理等丰富的功能,还能将电路板整体尺寸缩小到常规芯片大小,从而提高能效。
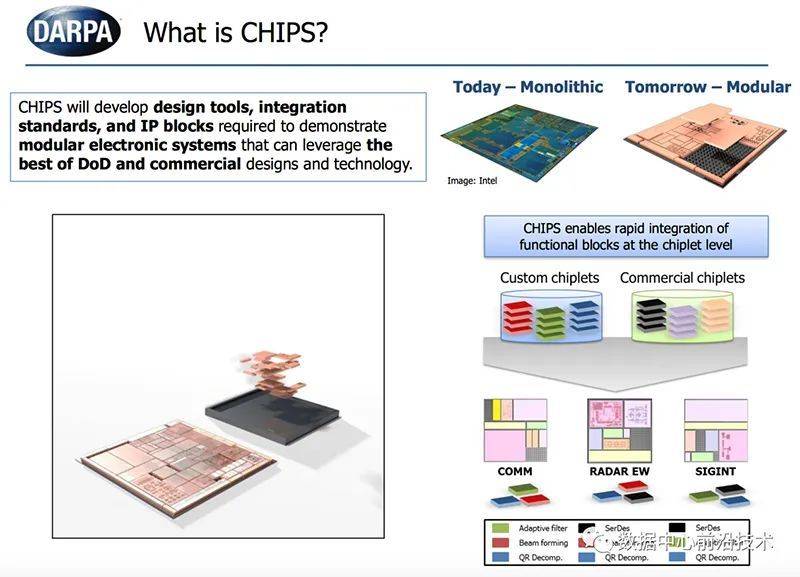
理想状态下,借助小芯片方法,芯片设计公司只需专注于自己擅长的IP,而不必担心其余IP,既有助于提升核心创新能力,又经由多种IP设计分摊了研发成本。
DAPRA向英特尔、美康、Cadence、思诺思科技等芯片企业以及一些大型军工企业、高校科研团队伸出橄榄枝,邀请他们作为项目的主承包方。
作为CHIPS项目的核心成员之一,英特尔推出高级接口总线(AIB),作为chiplet架构的免版税die-to-die接口标准。
例如,英特尔的Stratix 10、Agilex FPGA均使用相同的AIB接口来集成多种不同的小芯片。在CHIPS项目的支持下,许多不同企业及高校正在用AIB打造小芯片系统。
英特尔也是开放计算项目开放特定域架构 (OCP ODSA)基金会的成员,该基金会正在促进标准和技术的发展,以帮助实现高级封装策略。
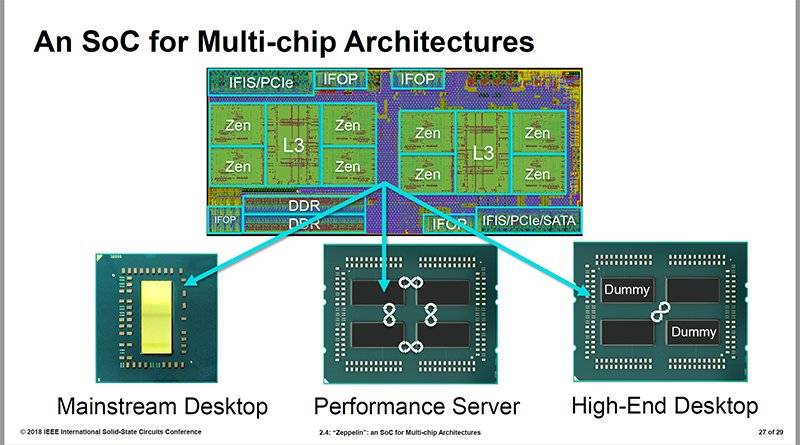
英特尔将其服务器处理器、FPGA、PC芯片等作为小芯片技术的商业试炼场,AMD亦将小芯片用在了服务器和客户端CPU中。
2017年,AMD在其Zen 2架构中用小芯片来开发Epyc服务器处理器Naples,随后又在次年推出的企业级EPYC处理器Rome中支持8个小芯片,最多支持64个核心。

AMD在2019年推出的Zen 2处理器系列,单核性能首次超过英特尔。
四、粘连小芯片的关键“胶水”
具体打造小芯片系统的过程,可就不像搭乐高积木那么简单了。
如何选择不同小芯片的设计方案、怎样实现小芯片间的连接等一系列权衡均会影响最终的处理速度、功耗和成本。
其中,为了达到接近或媲美单片芯片的性能需求,承担着“拼接”、“组装”功能的先进封装和互连技术尤为重要。
高带宽互连技术则在小芯片之间搭建了一条条“高速公路”,而2.5D、3D先进封装技术能大幅缩减芯片尺寸,提供更优化的复杂芯片集成方案。
这些技术的持续演进,正为小芯片的兴起提供关键的技术支柱。
1、AMD:Infinity Fabric与X3D
AMD从第一代Zen架构处理器开始引入了自研芯片内、外部互连技术Infinity Fabric(IF)。
该技术集数据传输与控制于一体,由用于传输数据的Infinity Scalable Data Fabric(SDF)和负责控制的Infinity Scalable Control Fabric(SCF)两部分组成。
IF总线可根据不同SoC优化配置,不仅能实现多个小芯片间的高速互连,也能实现服务器中多个CPU插槽间的高速互连,第二代IF总线还能提供CPU到GPU的连接,不过CPU到GPU的连接仍然基于PCIe。

AMD先进封装技术进化历程
在今年的财务分析师会议上,AMD透露了将于今年年底发布的Zen 3架构处理器中,IF总线将升级到第三代,可实现CPU与GPU之间的内存一致性,通过减少数据移动进一步提升性能并减低延迟。
下一代IF被称为Infinity Architecture,总线带宽是PCIe 4.0的两倍,最多支持8个GPU芯片的连接,而且还支持CPU到GPU的连接,预计这将给未来的APU带来更大的性能提升。

AMD第三代IF总线性能
按照AMD的路径规划,首批Zen 3架构处理器将率先用于EPYC服务器处理器中,之后再用于桌面处理器。
在此前的Zen架构上,AMD已尝试过多种MCM(Multi-chip module)封装。
据悉,AMD计划在未来的产品中引入一种结合2.5D和3D堆叠的新封装技术X3D,具体详情尚未透露,预计会现身于Zen 4处理器。
2、英特尔:EMIB、Foveros、ODI
英特尔的高级封装产品包括2.5D EMIB、3D堆叠Foveros以及两者组合而成的Co-EMIB。
嵌入式多互连桥(EMIB)可以被看作将两个小芯片连接在一起的高密度桥梁,在二维平面上实现Die-to-die的互连。
它是一块非常薄的硅中介层,微型凸点密度远高于标准封装基板。使用EMIB,可以准确在所需位置使用高密度互连,在其他位置用标准封装基板互连,这样就可以节约一定成本。
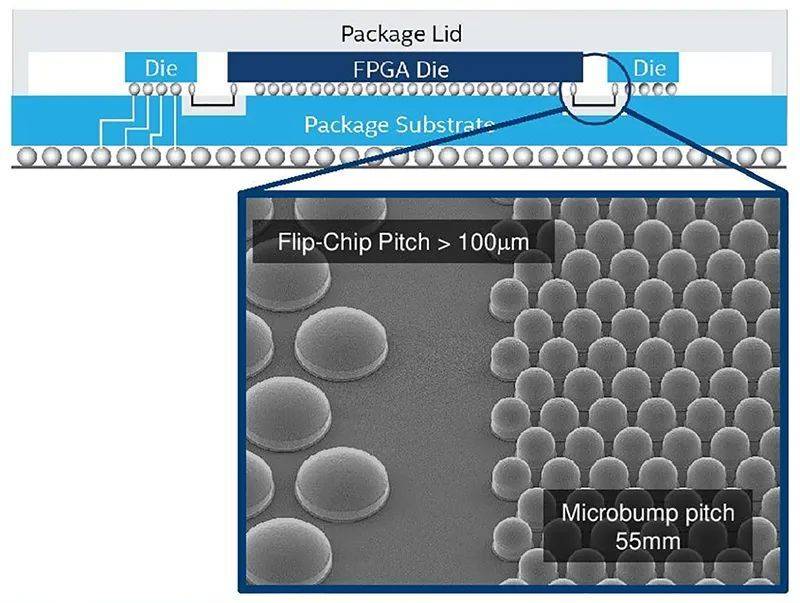
英特尔EMIB技术
英特尔当前有两种基于EMIB的解决方案。
(1)移动PC处理器Kaby Lake-G:用EMIB集成AMD Radeon GPU和HBM,然后在封装内用PCIe来集成GPU和英特尔CPU,从而实现更紧密地协作和更小的尺寸。
(2)Stratix 10 FPGA:中央FPGA周围有6个小芯片,包括4个高速收发器小芯片和2个高带宽存储小芯片。英特尔在示例中集成了来自3个不同代工厂的6个不同技术节点。
截至今年1月,英特尔已经出货了200万个基于EMIB封装的芯片。随着该技术日益普及,其应用范围将覆盖至PC、服务器、5G芯片、GPU显卡等。
除了EMIB外,英特尔还研发了3D封装技术Foveros,通过硅通孔(TSV),能像盖房子一样将逻辑芯片模块层层堆叠,不仅将不同IP模块有机结合,还节省了芯片空间,并保证功耗不会显著增加。
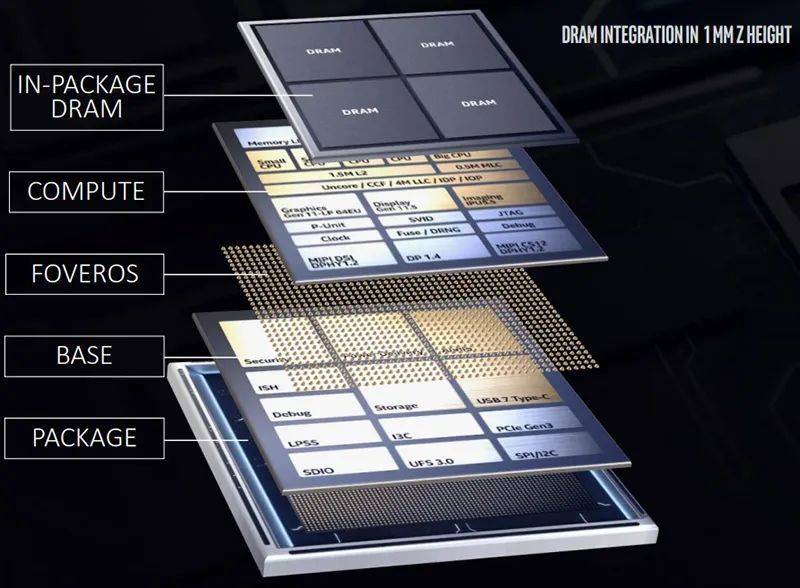
Lakefield内部架构
去年1月,英特尔发布Lakefield移动处理器产品,它有两个有意思的技术要点,一是有具有不同内核的big.little混合体系架构,另一个即是小芯片设计。
在Lakefield中,计算晶片(Compute die)负责计算处理,采用最先进的10nm、7nm、5nm工艺;基础晶片(Base die)主要实现I/O功能,性能相对不敏感,可采用22nm等成熟制程工艺。
为了适应更轻薄的物联网、边缘计算等场景,英特尔推出的Co-EMIB将EMIB的横向拼接能力和Foveros的纵向叠加能力相结合,通过EMIB连接多个3D Foveros芯片,制造出比单片芯片更大的灵活可扩展芯片设计,同时能实现近乎于SoC级高度整合的低功耗、高带宽、高性能表现。
在此基础上,英特尔提出全方位互连(ODI)微缩技术,顶部芯片可像EMIB一样实现小芯片之间的水平通信,也可以像Foveros一样通过硅通孔(TSV)与底层裸片进行垂直通信,从而实现以前3D堆叠无法达到的性能。
3、台积电:LIPINCON、CoWoS、SoIC
2019年6月,台积电在日本举办的超大规模集成电路研讨会(VLSI Symposium)期间展示了一颗自研7nm小芯片This。
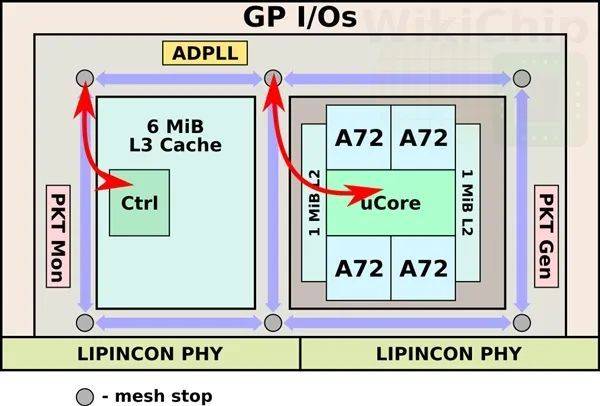
This尺寸为4.4x6.2mm,采用CoWoS晶圆基底封装和双芯片结构,一个芯片内建4个Cortex A72核心,另一个内建6MiB三缓。同时,台积电还开发了称之为LIPINCON互连技术,信号数据速率8GT/s。
Chip-on-Wafer-on-Substrate(CoWoS)是台积电设计的基于2.5D晶圆级多芯片封装技术,各芯片通过硅中介层上的微型凸块结合在一起,形成晶圆上芯片(CoW),然后将CoW减薄,露出TSV通孔。
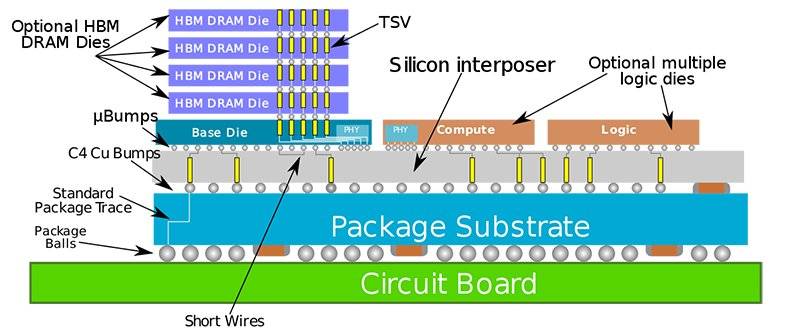
台积电CoWoS
CoWoS和InFO均为2.5D封装技术,前者侧重于高端市场,连线数量偏多,后者针对高性价比市场,连线数量相对较少。
基于CoWoS与多晶圆堆叠(WoW,Wafer on wafer)技术,台积电研发了新一代3D封装技术SoIC,可将不同尺寸、制程工艺及材料的小芯片组合。
相较传统3D封装技术,SoIC的凸块密度和传输成本更高,功耗更低,且能通过与CoWoS或InFO技术整合其他芯片,打造3D x 3D系统级解决方案。
4、CEA-Leti:有源中介层
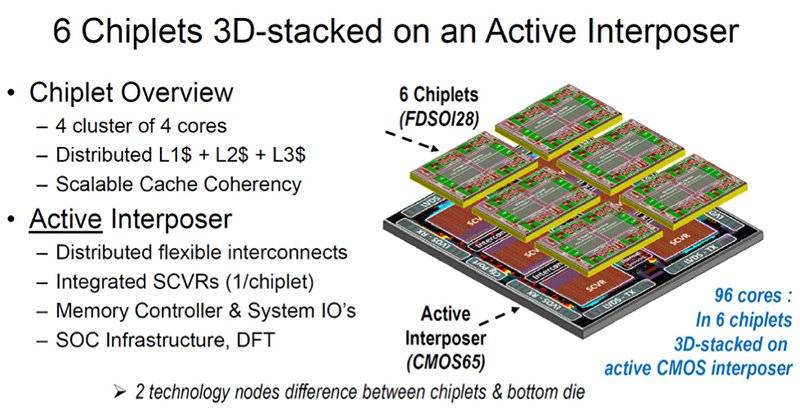
在今年的IEEE固态电路会议(ISSCC)上,法国研究机构CEA-Letu用6个16核小芯片创造了一个96核处理器,算力达到220 GOPS,功率为156mW。
硅中介层和嵌入式硅桥是满足数据速率和延迟需求的关键技术。此前常用于小芯片集成的大规模中介层技术有2.5D无源中介层、有机衬底和硅桥等。
这些技术普遍存在的缺点是不能实现灵活的远距离小芯片间通信,因而难以连接更多小芯片。它们还难以实现异构小芯片的平滑集成和低扩展功能的轻松集成。
对此,CEA-Leti引入了有源中介层(active interposer)技术和3D堆叠技术来克服这些限制,以实现大规模计算系统的设计。
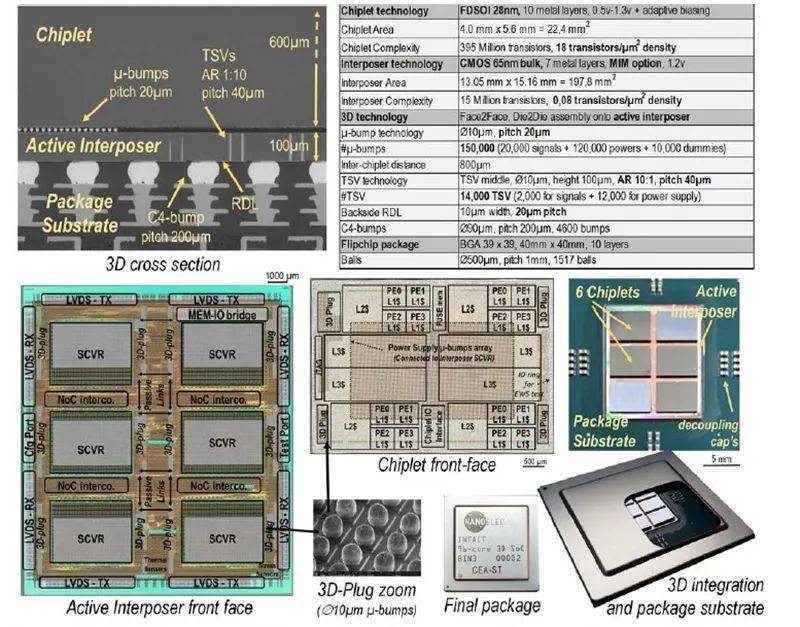
该芯片将6个采用意法半导体28nm FDSOI制造工艺的小芯片堆叠在一个到200mm²的有源中介层上,该中介层将直通硅通孔(TSV)嵌入到65nm技术节点。
CEA-Leti芯片显微照片、3D截面、封装和技术功能
每个小芯片包含16个MIPS32v1核心,有源中介层集成了开关电容器稳压电路、灵活的分布式互联和将内核的片上存储器各个部分连接在一起的网络,可提供节能的多核计算架构。
整个系统架构在所有小芯片计算区块之间提供了完全可扩展的分布式缓存一致性架构,这些架构通过活动中介层互连。该架构允许通过缓存层次结构轻松部署软件,从而实现高达512核的完整系统可扩展性。
CEA-Leti的科学总监Pascal Vivet认为,不同供应商的小芯片接口未必兼容,需要一种能将它们粘合在一起的新方法,而有源中介层是小芯片技术的最佳选择。
五、结语:通向下一节点的低成本路径
小芯片并非完美的,如今在小芯片探索的道路上,流量拥堵、散热、电源管理、测试等问题均是系统架构设计仍待克服的主要挑战。
尽管有DAPRA CHIPS、OCP ODSA等项目在着力推进小芯片接口标准化,但独立第三方小芯片供应的商业模式何时能在芯片产业中普及,当前尚未可知。
也许任何一种方法很难“单枪匹马”就挽救摩尔定律,但不可否认的是,小芯片这种新兴方法正在改变芯片的设计和集成策略,以更灵活的混合搭配系统方案,为芯片公司提供了迁移到下一个节点的低成本路径。
处于这样一场新革命的开端,无疑是一件激动人心的事。
参考来源:WikiChip,Mccoy
本文来自微信公众号:芯东西(ID:aichip001),作者:心缘

 05:30
05:30









 04:40
04:40
 04:36
04:36
 05:18
05:18
 14:47
14:47
 14:38
14:38
 13:22
13:22
 05:39
05:39
 04:57
04:57
 14:54
14:54




