2020-07-16 18:42


扫码打开虎嗅APP

本文来自微信公众号:神经前研(ID:NeuroHub),原标题《大脑中的反向传播》,作者Lillicrap.etc.,译者:山鸡、阿莫东森,题图来自:《X战警:逆转未来 》
俗话说得好:大脑要学习,突触可塑性少不了。大脑中的神经元能调控自身与其它神经元之间的连接强度,这一点我们早在上世纪七十年代就知道了[1]。
但我们也知道,学习的突触可塑性理论有一个缺陷,那就是我们不能通过单个突触的强度变化,来解释整个神经网络的行为:要明白学习,我们不能只考虑每个突触的可塑性,还要考虑它的行为学影响。因此,我们需要弄清楚大脑如何协调整个神经网络范围内的突触可塑性。
*译者注
[1] Bliss & Lømo, 1973
在机器学习领域中,人们在人造神经网络中研究突触应该如何表现才能实现效率最大化,这样也就能规避生物性的限制。为了得到这样一个人工神经网络,首先,我们要规定一个神经网络的结构,也就是该网络中有多少个神经元,神经元之间又该如何连接。
举个例子,人们一般用的都是含有多层神经元的深度网络(deep networks),因为这种网络结构在很多任务上都表现较好。接下来,我们需要定义一个误差函数(error function)。这样一个误差函数可以告诉我们:这个网络目前表现如何?我们应该如何调整其中的神经元连接来减少误差?
当前,“backprop”(即back propagation,反向传播之简称)是机器学习领域最常用、最成功的深度神经网络训练算法。用backprop训练的网络在最近的机器学习浪潮中占据着中流砥柱的地位,承担上了语音和图像识别、语言翻译等任务。
Backprop也推动了无监督学习(unsupervised learning)的进步,在图像和语音生成、语言建模和一些高阶预测任务中已不可或缺。与强化学习互相配合,backprop能完成许多诸如精通雅达利游戏,在围棋和扑克牌上战胜人类顶尖选手等控制任务(control problems)。

- Matt Chinworth -
Backprop算法将误差信号(error signals)送入反馈连接(feedback connections),帮助神经网络调节突触强度——这个套路已经被老一辈的监督学习(supervised learning,也就是根据外界提供的“正确目标”所进行的学习)算法用得滚瓜烂熟。
但与此同时,大脑中的反馈连接似乎有着不同的作用,且大脑的学习大部分都是无监督学习(在外界信息中找出其隐含的结构,并对之进行建模)。因此,自然会有人发问:backprop算法能不能告诉我们大脑是如何学习的呢?
虽然大脑与backprop之间存在诸多不同,但在本文中,我们想指出大脑有能力执行backprop中的核心算法。中心思想就是大脑能利用反馈连接来激发神经元活动,从而以局部计算出的误差值来编码“类反向传播的误差信号”(backpropagation-like error signals)。在这里,我们将一系列看似不尽相同功能的学习算法归入一个叫做“NGRAD”的算法框架中。
NGRAD(neural gradient representation by activity differences)指的是通过活动误差进行神经梯度表征的算法。NGRAD框架向我们展示了,我们也许能够在规避实际应用问题的前提下实现反向传播。这对于任何具有前馈和反馈连接的大脑回路都具有一定的讨论意义,但本文中主要探讨皮质结构中的表现。大脑皮质(cortex)具有多层的分级结构,且有许多特征与深度网络相似。
神经网络中的责任归属
学习,是为了适应。在谈学习之前,我们先来谈谈大脑本身的先验“知识”。毋庸置疑,大脑经过了演化的训练,本身就具有经过优化的神经结构和默认突触强度——这些都能算作大脑的先验“知识”。它们可能保证了动物能更有效地(用更少的错误尝试和反馈信息)学习。
但我们也知道,虽然演化使得动物常常自出生就拥有令人钦叹的能力,但是它们也需要大量的后天学习才能掌握另一些能力;后者包括了人类下围棋和象棋的能力、编程和设计电脑游戏的能力、写作和演奏钢琴协奏曲的能力、熟记(或迅速忘记[1])多语种单词和语法的能力、识别上万种物体的能力,还有诊断疾病和做血管微创手术的能力。
机器学习领域的近期研究告诉我们,这些能力依赖于强力而泛用的学习算法。因此,我们想在这里描述这样的学习算法,并展开分析它们是如何给多层神经元之间的连接,通过责任归属(credit-assigning)[2]来进行权重分配的。
*译者注
[1]译者注:比如我。
[2]译者注:我们可以这样来理解责任归属:假设你想要在全国法考中名列前茅,你于是参加了厚大法考的培训,每天按时定量观看罗老师的培训视频和阅读教材,同时还常跟同考的朋友一起讨论考题,最后成功取得佳绩;这时,你想要知道,对你取得佳绩最为重要的是哪一个(些)方面——这就是责任归属。通过责任归属,以后再参加类似考试的时候,你就可以着重注意那个(些)方面。
关联性方法
突触强度决定神经活动,神经活动决定网络输出,网络输出决定网络误差。因此,当我们想减少人工网络的误差时,我们可以在突触强度上做手脚。这个手脚该如何去做,是一门讲究分寸的学问:一个突触的强度改变并不会直接影响整个网络的输出,而是改变它的后突触神经元的活动和输出,从而改变它后突触神经元的后突触神经元的活动和输出... ...以此类推,最后间接影响整个网络的输出。
这个突触的影响力,也叫“投射场”(projective field),迅速扩张,因此改变一个突触强度所造成的影响,要根据它下游的其他突触来判定。
从概念上来讲,要决定增强还是减弱一个突触的强度很简单,我们只需要测量改变这个突触强度对误差的影响。在人工网络里做这类测量也很简单。首先,我们给这个网络一个输入,然后测量并记录它的基线误差(baseline error)。
然后,我们给某个突触增加一些噪音(noise),再给网络同样的一个输入,以此测量并记录它的新误差。最后,我们对比新误差和基线误差;如果新误差比基线误差更小,我们就接受这个噪音对突触强度的改动,如果更大,就否决这个改动。
假设神经网络的表现能够通过误差函数(error function),即该网络的输出值 [y1,...,yM] 与目标值[t1,...,tM]间的差值(比如通过误差的平方E=2 ∑l(yl−tl))来体现,那么,想要减少误差,我们只需通过调节网络中的权重就能够实现。
该权重可以表达为Wij ,其中权重差值ΔWij = −η(E′− E)ξij, η 是学习速率, E代表加入噪声之前的错误,E′代表加入高斯噪声ξij ~ N(0, σ ) i之后的错误。这个方法的问题在于,测量整个网络的误差来决定如何改变一个突触的强度,效率实在太低。

- Matt Chinworth -
当然,如果一些突触强度的改变比另一些对网络输出的影响更大,我们可以同时测量改变N个突触强度的效果,但这并不能解决上面提到的效率问题,毕竟此时我们需要N次尝试才知道该如何改动一个突触的强度来最小化网络误差。其实,我们可以通过扰动神经元的输出,而非它们之间的连接强度,来升级这类“权重扰动”(weight perturbation)方法。
升级后的“结点扰动”(node perturbation)方法能计算一个神经元的活动对它的输出权重的导数,从而加速学习过程。但这种方法仍然非常慢,而且随着网络体积的增加,网络的表现会急剧下降。我们认为,大脑也许在某些学习过程中会使用这些扰动方法。但令我们惊讶的是,至今仍未有任何经过扰动方法训练的神经网络在复杂问题上(例如归类含有多种物体的自然图片)取得过成功。
而Backprop算法与扰动算法不同,backprop不测量,而是直接计算改变一个突触强度对整个网络的误差的影响。这在人工网络中可行,是因为我们(程序员)知道整个网络中所有的“突触强度-网络输出”因果关系。相比之下,基因型(genotype)和表现型(phenotype)之间的因果关系一般都受到未知环境因素的调节,因此演化似乎只能测量基因型变动的后果,而不能对其进行计算。
反向传播
Backprop利用微积分中的链式法则(chain rule)来计算突触强度上微小的变动会对整个网络的误差有什么影响;并且,backprop能同时对所有突触进行计算,因此所需时间仅相当于一次正向传播(forward propagation)的时长。做到这些的核心是对“误差信号”以递归(recursive)方式进行链式法则运算。在一个多层级神经网络中,一层中神经元的误差信号是通过上一层神经元的误差信号计算得出的。
因此,误差计算在最底层开始,向上回溯——误差就这样在网络中“反向传播”。当每个神经元的误差信号都被算出来后,只要改动每个神经元与它们的前突触神经元之间的突触强度,使得它们的后突触神经元活动向着减少误差的方向调整,就能降低网络误差。
通常情况下,backprop都被当成一类需要外界提供与输入信号对应的显性输出靶点(explicit output targets)的算法。实际上,backprop由于以递归方式利用了链式法则,因此能更普遍地计算网络中一个部分的活动变动对其下游部分的活动所造成的影响。也正因如此,backprop可以被广泛用来计算多层级网络中的责任归属。
本文中对backprop的分析限于监督学习;但是切记,反向传播的信号不仅可以是输出与外界提供的靶点之间的差别,它还可以是一个时间差分误差(temporal difference error)、一个强化学习中的策略梯度(policy gradient),或是对一个无监督算法的重建或预测误差(reconstruction/prediction error)。即使是一个缺乏外界靶点的生物,也完全可以自己产出这些信号。
译者评论
backprop成功的关键在于:它可以在很短的时间内对外界输入进行良好建模;这种建模不是一蹴而就的,而是在学习的过程中不断完善的。对外界环境中的基础元素进行内源表征可以使网络的中间层对不同的物体,利用它们的共享元素,进行表征(wow这就是3R吗!reduce, refine, reuse)。
Backprop的一个特点(大概也是这类算法成功的关键)就是能够迅速对输入信号在网络内建模,以产生内部表征(internal representations)。内部表征并不会直接出现在输入信号或输出靶点中,而需要在不断的学习中慢慢被发掘出来。
内部表征包含用处甚多的“一砖一瓦”(building blocks),比如对角落、形状的碎片、词语的语义等等的表征。网络的中间层能利用这些“一砖一瓦”来对许多不同的物体进行编码。这样,网络就能用旧的“砖瓦”来对新信息进行表征,这也就允许了网络进行一般化(generalize)。
- Matt Chinworth -
Backprop算法的实现有两大基石,而两者也都能在生物网络中被实现。第一,单个突触的连接强度要能被改变:生物网络中,学习行为对应的突触可塑性(例如依赖于发放时序的可塑性(spike-timing-dependent plasticity))能改动单个突触的强度。第二,网络内部的神经元需要收到反馈连接,这样网络才能计算需要的突触强度变动。
如果一个学习算法能用精确的向量反馈来计算单个突触的强度变动,以此来优化网络输出,那么我们就将其称为“类backprop”算法。这种反馈连接可以是直接的“自上而下”,皮质-皮质(从高级到低级皮质处理区块)连接——在视觉V2和V1之间就存在着这样的连接。这种连接也可以路经丘脑(thalamus),通过皮质-丘脑-皮质回路来将高级信息传播给处理低级信息的脑区和其中的神经元。
反馈连接在皮质计算中的角色仍不明晰,因此我们还不肯定皮质使用了类backprop的学习算法。但是,既然反馈连接能调控神经元发放,而发放决定了突触强度的调节,那么这些反馈连接所携带的信息自然能影响学习。
如果我们将皮质理解成一个高效的学习机器的话,那么反向传播就是皮质运算的一个好候选模型。话虽如此,皮质中的这些反馈连接能如何模拟反向传播,这当中还有很多细节需要诠释;此外,一些最容易想到的反向传播机制,在生物系统中并不现实(下文有与此相关的讨论)。
但这些容易想到的机制不现实,并不意味着backprop就不能引导我们理解大脑的学习机制。Backprop作为一个强劲的学习算法,其核心思想(神经网络能利用反馈连接提供的信息,以改变单个突触强度的方式来进行学习)在许多应用领域中都屡试不爽,因此我们需要探究大脑利用反向传播中没那么容易想到的机制的可能性。
译者评论:大脑皮层与人工神经网络在结构上存在着许多差异,但皮层各区域存在着一些共性的计算机制,我们认为backdrop可以帮助我们理解共性的机制以及突触的差异?
当然,我们应当承认,皮质在许多重要的方面上与人工神经网络有不同之处。举个例子:皮质的各层(I层到VI层)和各区(例如V1和V2)在人工神经网络里找不到一一对应的部分。另外,在皮质的不同区域里,细胞种类(cell types)、连接规律(connectivity)和基因表达(gene expression)都有所差异;一个皮质脑区与其他皮质和皮质下脑区之间,都会有众多连接——而这些还只是皮质和人工网络种种不同中的一部分。
但虽然如此,各个皮质区域之间还是有一些广义的相似之处的,其中就包括微柱(microcolumns)的普遍存在和皮质区域之间的典型连接规律——这些相似之处说明,皮质运算也许有泛用型的框架,而明白这些框架也许有用。并且,我们认为大脑需要用一个类似于backprop的算法来协调突触强度的变动。
大脑中的backprop?
我们目前缺少大脑使用“类backprop”算法进行学习的直接证据。但是以往的研究表明,backprop训练的模型能逼近大脑中的神经现象,例如后顶叶皮质(posterior parietal cortex)和主运动皮质(primary motor cortex)中神经元的特性。神经科学界对视觉皮层的建模研究正在陆续不断地提供新证据。
这些研究已经发现,利用由backprop训练的多层模型来对物体进行分类,其对物体的表征比别的模型都要更接近于灵长类大脑中视觉腹侧流(ventral stream)的表征。其他未由backprop训练的模型的表现则不如backprop网络;此外,它们得出的表征与大脑下颞叶皮质(inferior temporal cortex)和backprop网络中的表征并不相符。

- Matt Chinworth -
虽然backprop训练出的网络能得出与大脑大致相符的表征,但是近期的研究也发现,目前的模型还不能解释一些人类在物体分类任务上的表现。尽管如此,由backprop训练的模型似乎在很多任务上都比其他模型要更逼近大脑。
表现良好和表征相符,这两点并不足以说明大脑一定利用了与backprop相似的算法。在算力充足的将来,也许在复杂任务中表现良好的网络在不使用向量反馈算法的前提下就能训练出来。我们现在能肯定的是,backprop的实用性和高效率表明,大脑可能利用了由误差驱动的反馈进行学习。
在机器学习领域内,目前还没有人能用非backprop算法训练出高效的、能应对复杂任务(例如物体分类)的深度网络。如果你想用只有标量反馈信号的算法(例如演化算法和REINFORCE算法)来训练能应对复杂任务的高效深度网络,那么等待你的只有失败。
由backprop训练的深度网络,不仅可以提供能产出与大脑计算相符的表征,还能解释感知学习中,感受野的变化大小和变化时间。此外,backprop网络还能解释在某些动物和人类学习过程中的阶段性变化(stage-like transitions)。
其他研究表明,皮质II和III层的神经元似乎会计算实际和预测的感知事件之间的误差,而视觉皮层中,在连续处理步骤中的神经动态与backprop中的层级误差信号相似。这些发现说明,皮质中的反馈连接可能的确会在多层的表征中驱动学习行为。在倒数第二节,我们将会总结支持我们神经机制假设的新发现。
使用神经活动差异进行误差编码
在现存的机器学习机制中,许多最近的模型都使用了通过神经元活动状态的改变来内隐地驱动突触改变的方式。这与以往通过坡度信号改变来外显地驱动学习的方式有所不同。当backprop进入主流视野之前,包括玻尔兹曼机(Boltzmann machine)在内的许多神经学习网络已经身体力行地践行了这个理论。
这些神经网络通过活动状态在两个阶段传播间的时间差异来进行更新(update)计算。近来,一些神经网络还使用了局部环路的神经元组间活动状态的差异,或是神经元内各部分间(注:神经元可分为树突、胞体和轴突三部分)的活动差异来计算更新的方法。
我们把上述使用活动阶段差异来驱动神经元改变的学习机制统述为NGRAD,把支撑这种学习机制的理论成为NGRAD假设。该假说最有吸引力的地方在于它规避了两种截然不同的定量,也就是活动(activities)和错误(error derivatives),的传播。NGRAD的观点是,来自目标刺激、另一种形态(modality)、或是宏观时空背景的高层级活动能够将低等级活动推(nudge)向与高级活动或是期望结果相一致的数值。
在这样的前提下,在低层级活动中诱发的改变就能进而促进反向计算,即仅仅依靠层级内的信号就能够实现更新计算。综上,NGRAD的核心在于:自上而下的神经活动能够在不依靠层级间外显的错误信息传递前提下驱动学习。
GeneRec是上述神经网络算法中较为成功的一个。GeneRec在玻尔兹曼机算法和循环算法中汲取灵感,以下述方式训练多层级循环网络(multilayer recurrent networks):在“负相”(negative phase)时传来了一个输入信号,然后循环网络活动状态达到一个平衡。而在“正相”中,当输入信号进入网络时,输出信号可能紧抓着或正被推向它的目标值,而活动状态将再一次达到平衡。
GeneRec的学习规则是简单而又局部的:每一个突触权重改变都应等比例的与突触前/后神经元活动在正/负相的产物相关联。
- Matt Chinworth -
包括对比赫布式学习(contrastive Hebbian learning),Almeida/Pineda算法与亥姆霍兹机中(Helmholtz machine)的醒-眠算法(wake–sleep algorithm)在内的一系列其他神经网络学习都应用了近似的逻辑。我们认为这种逻辑中最重要的一点在于,它们应用了在不同时间节点以及不同部位活动状态,来捕捉引导学习的误差信息。
新的研究工作在探讨backprop生物层面上的可实现性时,也都回归到了这些问题上——比如平衡传播(equilibrium propagation)就应用了与GeneRec和对比赫布式学习相类似的原则。
进一步来谈,许多模型还检测了在取消负相的情况下能否实现NGRAD学习。这一系列模型应用了预测编码,利用神经元间/神经元内各部分信息的不同(而非时间节点上的不同)来计算预期。尽管NGRAD只计算层级内部的错误,而不是像backprop网络或是反馈对齐(feedback alignment)那样计算层级间的错误传递,这类神经网络仍旧能够达到与backprop近似(甚至相同)的计算效果。
为了一探层级内部活动差异的计算如何引导学习,我们检测了在神经深度学习处理系统交流会(Neural Information Processing Systems workshop)上首次提出、并由李(Lee)等人完善的神经模型。该模型的核心有二:自编码器(auto-encoders)将信号从上往下传导并激活早期层级,以及其诱发的差异促成的权重更新。在下文中,我们将介绍自编码器,以及在生物学限制下,自编码器是怎么成为深度学习算法的基础结构的。
自编码器
那我们从自编码器开始!自编码器是一种用来重构输入刺激的网络。最简单的自编码器将一个输入信号向量x,在隐藏层级通过权重矩阵以非线性的方式将其转换成活动向量h = f (x; W ) = σ (W x) ,其后通过反向权重矩阵将其再转换为新的向量x̂ = g(h; B) = σ(Bh) 。
自编码器的训练不借助外显标签,这是因为初始向量与重构后的向量之差(e = x − x̂ )即是用于驱动学习的误差。这里提到的误差是由输入层级中的神经元计算,并通过隐藏层级反馈至输入层级从而调整权重的。在NGRAD框架中,最重要的理念是自编码器将高级层级处理的活动目标(activity targets)反馈至早期层级,从而通过局部差异驱动学习。
目标传播
图3a展示了目标传播,即使用一系列层级排布的自编码器进行深度学习的运行过程。我们通过网络中的层级将活动正向传播从而获得一个预测结果,随后我们使用逆函数将该预测结果反向传播。假设我们有这样一系列自编码器,每一层自编码器中的隐藏单元(hidden units)都是下一个自编码器的输入单元:
在正函数中,对于层级:
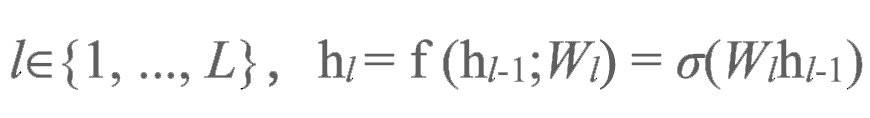
而逆函数中,对于层级:
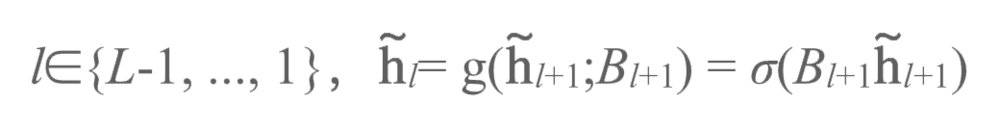
下文中我们将把神经网络中的输入刺激标注为:
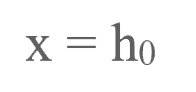
输出刺激标注为:
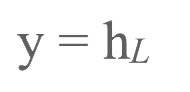
输出结果标注为:
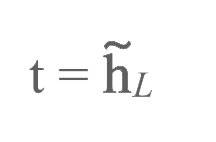
此外,我们在下标中加入了加权矩阵:
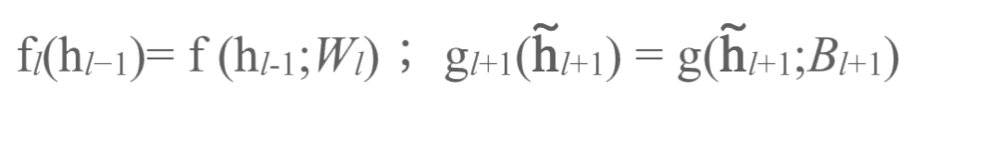
如果自编码器是完美的,那么逆函数中每一个高级层级都应对应了其下级层级的函数:
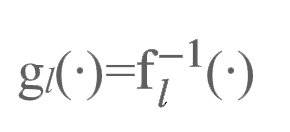
进而有:
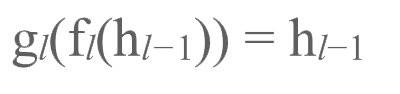
当正、反向传输均完成后(且正向传输是在反向传输之前完成的),正反向传输之间的活动目标差值
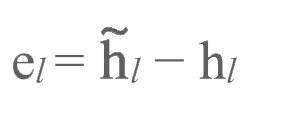
将会通过:
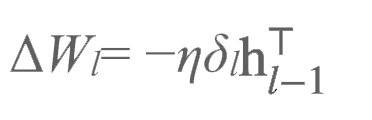
驱动学习,即:

通过自编码器产生的目标驱动学习的理念本身很优雅,但在实际神经活动中这种假设存在着一些问题,这主要是由于神经元中很难实现完美的正反传播。
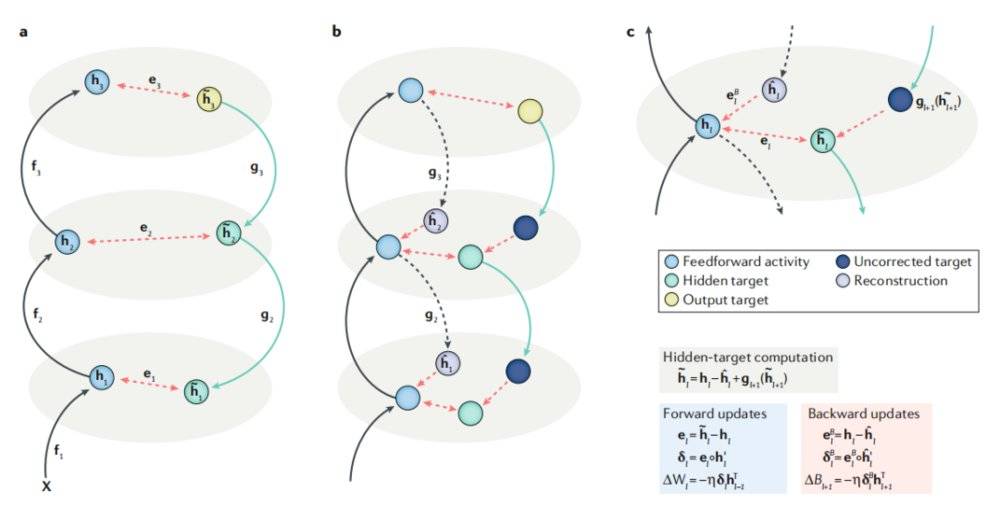
图3a(左)、3b(中)、3c(右)
—
https://doi.org/10.1038/s41583-020-0277-3
目标间的传播差异
上述目标传播是是理想中的完美情况,但我们也谈到了,自编码器在现实中是无法完美地将目标反向传播至早期层级的。这种不足可以通过训练神经网络进行反向加权来进行弥补。在正向传播的过程中,我们要尝试利用下一层级来重建本层级的神经活动(如图3b所示):
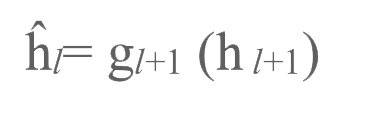
自编码器的反向传播由此产生了分层误差(layer-wise errors):
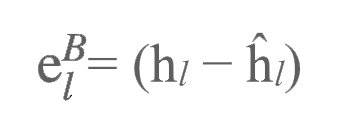
我们利用分层误差调整反馈加权:


这意味着神经环路有了元学习的能力。
接下来,我们将l+1层级的调整目标:
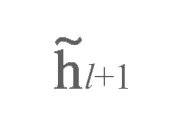
反向传播至至层级l(见图3b, c中的绿色圆球):
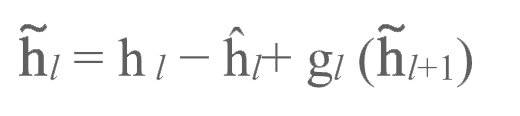
这使得自编码器能针对部分输入刺激得到更好的发挥。最后,我们像前文所述的那样使用这些调整过的目标对正向加权进行更新:
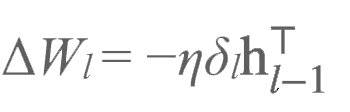
这种学习过程叫做目标差值传播(difference target propagation,即DTP)。
在图片分类任务中,DTP训练是行之有效的。经过时间推移,神经网络通过权重与节点扰动习得了权重更新。人们仍在更具挑战性的数据库及更复杂的结构中探索DTP算法的表现。一项近期的研究显示,针对ImageNet任务,DTP在大型卷积网络中的表现不如反向传输网络。
此外,DTP算法没有解决实时学习(online learning)问题,也没有提供在生物结构的基础上实现正向、反向传播的思路。无论如何,这种算法为我们提供了一个在多层级网络中层级间活动差异如何驱动学习的思路。近来的一些研究提供了大规模任务中恢复表现(recovering performance)的路径。
我们强调了,上述算法在正反向传播中使用了同类信号,且使用了层内局部活动间的差异来计算误差。但我们不排除大脑可能应用了更近似于backprop的算法。或许有的人认为,将特征预测进行正向传播,误差信息进行反向回馈的方式,与神经元的工作方式更为类似,但目前我们还没有找到能够支撑这种假设的证据。
与之类似的另一种理论是,或许存在着第二类特殊的神经元仅负责层间误差反馈,再将这些反馈在不干扰特征加工(feature processing)的前提下进行正向传播。我们不清楚该如何有效地实践这些理论,但要想更深入地理解多层级责任归属是如何在神经环路上进行权重分配的,我们同样不该忽视这些除NGRAD之外的可能性。在现存的多层级责任归属算法中仍没有任何一个能够完美解释大脑皮质环路的神经生理学机制,但它们能为神经学未来的探索提供方向。

- Matt Chinworth -
现存的NGRAD模型为大脑可能如何运用backprop算法提供了更深层面的理解,但关于这种加工形式能够如何在神经组织中成功实现,仍有许多问题等待着我们解决。
要想在神经环路中发挥作用,NGRAD需要满足以下两点条件:1. 协调前馈和反馈通路,2.计算神经元活动的规律差异,并据此进行突触调节。我们仍不清楚支持上述调节的生物学原理,但近来一系列实证研究提供了一些可能的解释。
在电脑上运行时我们不需要过多在意前馈或反馈处理中涉及到的记忆环节。对于这种计算在神经元中得到实现的可能性,最早被提出的一种是:人脑中可能存在一组独立的、用于反馈处理的“误差”神经元。
DTP也可以通过上述方式得到实现,但在皮层中不存在不受反馈活动影响的前馈神经元——在大脑皮层中,区域内部的前馈与反馈是交互影响的。因此,如果区域A向区域B传递了一个前馈连结,A很可能会收到B的反馈信号。
假设在大脑中前馈与反馈回路应用的是同一组神经元,这将为我们理解皮层中的backprop学习提供非常重要的启示。这可能意味着大脑中存在着时间节点上的多路复用(multiplexing),即同一组神经元中先出现了前馈处理,其后被反馈处理所替代。这种假设暂时还没有得到任何直接证据的支持:大脑中的前馈与反馈通路是被同时激活且相互作用着的。
当我们谈到backprop的神经学基础时,我们一般假设前馈与反馈突触对于神经元施加了相近的功能性影响。倘若这种假设是成立的,时间节点的多路复用对于计算活动差异就变得十分必要了。可事实上,神经元中各部分的无论是功能上还是结构上都存在着差异,而神经元活动在各部分间的表现也相差甚远。
举个例子,第五层级神经元的顶簇树突在电神经学上的表现与胞体和基底树突有所不同。顶簇树突能接收到直接来自大脑皮层的高级区,或间接通过丘脑中继的反馈连接。并且,这些树突能够作为半独立区域,仅在特定情况下才与胞体进行交流。
此外,前馈连接主要作用于椎体神经元中的基底树突部分,而这一部分在功能上是与其他部分相独立的,也可能遵循着不太一样的可塑性规则。
如今,人们已经开始探索更具可行性的神经计算模型。这种模型应当在神经元的各部分实施不同的计算功能。将单个神经元的角色复杂化,有助于我们规避神经元点状流程模型(point-process neuron models)中出现的种种问题。
如果我们能够细化细胞内部的信息处理区域,那么前馈与反馈处理便可能同时出现。单个神经元中各部分间的交流能够以反向传播的动作电位及高原电位(plateau potentials)等方式出现。
进一步来谈,细胞内各部分之间的双向交流还可能受到其他因素的影响,比如有些抑制性中间神经元会抑制椎体神经元中特定部分的活动,独立的树突则使大脑皮层中细胞群簇状发放导致的多路复用(burst ensemble multiplexing)成为可能,并用此策略来同时进行前馈和反馈处理。由此可见,高频簇状发放和单个的动作电位可以在细胞内的不同部分发起,而这些不同的信号又可以进行前馈和反馈传递。

- Matt Chinworth -
关于生物实现性的另一个令人振奋的细节在于,(除backprop以外的)NGRAD模型会通过对低层级活动的反馈调节来进行学习。生理学研究中有自上而下反馈主动调节自下而上信息处理的观点,这与NGRAD模型中的上述细节不谋而合。综上所述,新的研究证据为责任归属的生理学合理性提供了新的解释思路。
在神经科学中,大脑皮层是如何通过突触变动来提升复杂多阶段网络的学习能力,依然是现存最大的问题之一。反馈连接影响的发现为解决这个问题提供了可能的方向,这给神经科学界带来了极大的震动。然而在惊喜之余,研究者们很快发现了反馈调节的缺陷:反馈调节网络并不能在人工智能系统中发挥很好的表现,且该算法还面临着生理可行性的问题。
随着算法性能的提升、数据库的扩充以及一些技术改进,backprop能够在多层级神经网络中实现与匹敌人类能力的计算表现。我们认为backprop为我们理解大脑皮层的学习提供了一个很好的理论框架,但我们仍不清楚人类大脑该如何实现反馈运算。
在将backprop与大脑中学习活动相拼凑的进程中,我们还缺少了许多块重要的拼图。尽管如此,backprop如今的发展已与三十年前大相径庭。研究者们曾经认为backprop算法不具备生物可行性,因而神经科学能够从这类网络中获得的知识极为有限。
然而现实是,在深度学习网络中,利用表现梯度进行学习的效果非常好。由此看来,也许调控大脑的千万个基因理应带着大脑的亿万个突触向着计算梯度的方向缓慢进化。
原文:https://www.nature.com/articles/s41583-020-0277-3 https://doi.org/10.1038/s41583-020-0277-3
本文来自微信公众号:神经前研(ID:NeuroHub),作者Lillicrap.etc.,译者:山鸡、阿莫东森

 02:01
02:01









 07:08
07:08
 32:45
32:45
 10:00
10:00
 02:03
02:03
 12:33
12:33
 01:41
01:41
 34:59
34:59
 14:58
14:58
 07:30
07:30


