2016-08-03 11:59


扫码打开虎嗅APP

本文来自微信公众号:爱分析(ifenxicom),虎嗅获授权发表。
据中国企业联合会数据显示,中国市场每年因为诚信缺失造成的经济损失约为5,000多亿元。征信行业的成熟发展,不仅能够促进经济的健康繁荣,还有利于维护良好的社会秩序,促进构建社会信用体系建设。
对比美国市场发展阶段,中国尚为初期发展阶段,还处于“小荷才露尖尖角”的状态,既蕴含着巨大的市场空间,也需要众多参与者继续不断开拓。
未来还需逐渐实现数据全覆盖、确定市场主体地位、明确立法,带动征信市场的发展和应用范围的扩大。
数据源争夺战还未打完
提到征信,首要便是数据源问题,数据源是征信行业的基础生产材料。
在美国成熟市场中,数据采集并非征信产业链中的核心环节。然而在中国,数据源争夺战还未结束,各家机构仍将足够多的数据源视为核心竞争力。
之所以仍处于数据源争夺战:
一是数据采集场景割裂化
有效数据的采集场景不仅包括银行、保险、公安、公共服务部门等线下场景,还包括电商、社交等互联网线上平台。
征信机构需要对接不同部门和平台,建立广泛的数据连接,形成数据聚集效应,才能在行业中占据有利地位。但是,这些数据的采集场景是互相割裂的,仍是一个个数据孤岛,并且数据源存在散乱的问题。
其中,金融场景的数据未能实现统一征集和标准化处理;公共部门的数据则是由公安、法院、教育及其它事业单位分别开放;生活场景的数据则是分散在线上线下的各类场景中。
大部分征信机构通过自爬、合作、购买等方式,从这些有限的场景中整合数据,由于整合是通过市场化的方式进行,因此关于数据源的竞争尤为激烈。
二是数据获取渠道有限
中国征信市场不仅获取信用数据的渠道极其有限,并且缺乏专业的数据提供商或交易平台,导致征信机构对于数据源的占有成了关键竞争优势,并在采集数据上耗费了大量成本。
同时,美国征信公司会通过收取费用的方式,相互之间共享数据。但是在中国,由于数据源往往涉及核心竞争力,大多数机构并不愿意公开共享,数据之间的交叉融合很少,也影响到数据的应用和拓展。
目前,只有央行征信中心能够做到数据共享。据波士顿咨询公布的数据,央行共收录8.6亿自然人,以及1,811家企业和其它组织信息。
其中,有信贷数据的只有3.5亿人,剩余5.1亿人只有简单的身份信息,并没有其它金融信用数据,尚有5亿人根本不在央行征信系统覆盖范围内。对比全球征信巨头Experian,其数据已覆盖全球8.9亿人和1.03亿个企业。
除央行征信中心外,已经有社会征信机构尝试打破数据孤岛、建立数据共享,但是却面临着诸多困境,如多数金融机构担心数据披露而不愿进行数据反馈,导致进展缓慢。
然而,建立数据共享有利于数据形成闭环,优化数据资源供给,也会使征信机构不再将占有基础数据视为关键优势,而把更多的注意力放在征信产业链的其它核心环节。因此,也许解决了数据共享这一问题,数据源争夺战才能真正告一段落。
三是最强相关数据源稀缺
在数据源中,强变量是指信贷、信用卡、外汇、民间借贷等金融交易数据,往往掌握在传统金融机构手中;中变量是商品生产、销售、流通、消费等环节的交易数据,主要来自各类电商平台;弱变量则是社交、游戏等数据,大多源于互联网平台。
由此可见,金融属性的数据是最强相关的数据,而这类数据往往在传统金融机构手中。大多数征信机构能够获取的,是社交记录、个人消费记录等相对弱相关的数据,但却难以获取最为重要的金融数据,导致有效数据比较有限。
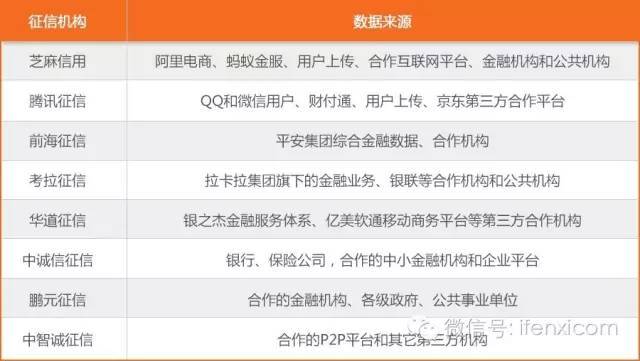
8家个人征信试点机构的主要数据来源
以芝麻信用为例,其利用互联网和用户自行上传资料,获取线上用户行为数据,并通过与公共部门、商家合作的方式获得线下数据。同时,对收集的各类信息进行评估,给出相应的芝麻分。
芝麻信用评估的信息综合了用户的信用历史、履约能力、行为偏好、身份特质、人脉关系等五个维度。
其中,信用历史指信用账户的还款记录及信用账户历史,履约能力是享用各类信用服务并确保及时履约的能力,均属于强变量;行为偏好则是指在购物、缴费、转账、理财等活动中的偏好及稳定性,是中变量;而身份特质和人脉关系则属于弱变量。
同时,数据质量也是大多数征信机构面临的问题。由于没有统一的数据采集和处理规范标准,往往出现数据录入错误、信息缺失、冗余重复、信息主体不明等问题,导致征信机构成本增加、效率变低。
市场格局仍以公共征信机构为主导
现有中国征信市场中,公共征信机构和民营征信机构并存,并且政府主导型的公共征信机构仍然占据主导地位。而私营征信机构的数量和规模都相对较小,尤其是私营个人征信机构还处于刚起步的阶段,个人征信牌照尚未完全放开,还没有形成对公众的补充。
同时,在市场格局上,社会征信市场中还未出现一家独大或已有巨头的局面,因此,关于未来市场发展的想象还具有无限可能。
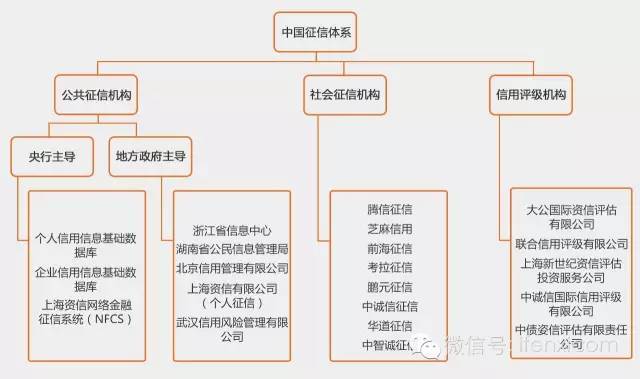
中国征信体系
另外,在此系列报告的首篇文章中,通过分析美国征信行业特点,可以看出其基于纯市场化运作,具有针对行业细分,对接场景非常全面的优势,但是也存在市场淘汰过程慢,代价高的问题,同时,市场化运作,对于政府监管及其基础环境的要求极高。
在国内,民营征信机构已在企业征信领域中占据重要地位,并初步建立起市场化运作模式。而个人征信领域还处于从公共向市场化过渡的阶段,我国从2003年开始试点个人联合征信。
到2015年央行要求芝麻信用、腾讯征信、前海征信、鹏元征信、中诚信征信、中智诚征信、拉卡拉信用以及华道征信等八家机构开展个人征信业务试点,期限半年。
现在已过去一年多,还尚未发放个人征信牌照。
牌照迟迟不发的原因,可能是在采集数据的过程中,存在采集方式不当、滥用数据、侵犯合法权益、授信不平等的现象。而现在立法对于数据采集、平等授信等方面尚不完善,可见央行在保护隐私、数据规范使用方面依然十分谨慎。
未来个人征信市场的发展关键还是在于牌照的发放,以及市场能否进一步放开,以保证更多的民营征信机构参与进来,推动个人征信市场化取得实质性进展。
差异化定位还在探索中
美国征信市场中已形成了泾渭分明、分工明确的格局。例如,三大个人征信机构Experian、Equifax、TransUnion是负责收集、整合和处理消费者个人信用记录的机构。
这类机构在收集个人信用数据后,会采用信用评估公司Fair Isaac推出的信用评分模型——FICO,对消费者信用进行评分。而FICO本身并不采集和存储数据,只是通过不同的变量、参数,提供信用分数计量算法。
除此之外,还有获得京东投资的ZestFinance,其核心竞争力在于数据挖掘能力和模型开发能力,其擅长利用10个预测分析模型,对上万条原始信息数据快速进行分析,并得到最终消费者信用评分。
而在中国征信市场,各征信机构在征信产业链并没有明确的分工,或者形成各司其职的格局。大多数征信机构的业务囊括了数据采集和处理、分析和建模,也有一小部分机构是专注于产业链中的某一点。
从产品上看,大部分征信机构都拥有信用评分、信用报告和反欺诈等服务,产品种类比较趋同,反映出中国征信行业在形成差异化优势和定位上,仍处于探索阶段。
另外,部分征信机构各自已经建立了自己的评分模型,银行通过借助这些外部力量合作建模,但从全国整体市场来说,尚未出现一个类似于FICO那样被大范围使用、极具权威性的评分模型。
盈利模式单一
在客群上,全球征信巨头Experian,已实现了金融服务、零售、电信、公用事业、保险、汽车、医疗、慈善机构、娱乐休闲、房地产和公共部门等行业的全覆盖。同时,其2015年收入为48.1亿美元,其中非金融领域的客户贡献了70%,而传统金融机构贡献收入只占比30%。
而中国征信产品主要应用于金融信贷服务,以及部分反欺诈、身份验证、信用决策的生活场景,而金融机构仍是征信产品的主要客户。
在金融信贷领域之外,八家试点机构已经在拓展更多元的征信应用场景。相信未来征信产品的应用场景将更为广阔,也将会为收入来源多元化带来巨大的空间。
在产品上,目前国内几乎全部征信机构,收入主要来源于数据调取量。央行征信中心日均数据调取量约为80-100万次。商业银行等机构查询企业信用报告基准服务费为每份60元,查询个人信用报告基准服务费则为每份5元。同时,国内社会征信机构中,第一梯队的日均数据调取量在50万以上。
而Experian收费模式则更为多元,在其2015年收入中,信用服务收入占比49%,决策分析收入占比 12%,市场营销收入占比 18%,消费者服务占比21%。同时,Experian日均生产380万份信用报告。
目前,国内已有一些征信机构转型为信贷公司,而征信需要保持绝对的第三方客观中立立场,因此,信贷和征信必然是不可兼得的。
法律保障体系不完善
征信法规制度方面,我国逐步建立了以国家法规、部门规章、规范性文件和标准的多层次制度体系。
我国征信行业立法始于2005 年的《个人信用信息基础数据库管理暂行办法》,之后相继出台了《征信业管理条例》、《个人信用信息基础数据库管理暂行办法》、《银行信贷登记咨询管理办法等,逐步建立了多层次制度体系。
然而,依然存在法律保障体系不完善的问题,一是所依赖的《征信业管理条例》、《征信机构管理办法》,主要是行政法规和部门规章,法律效力较低。
二是未与民法、金融机构相关法律、消费者保护法等形成有效的衔接,对于金融信用信息基础数据库的使用规定并不明确,在有力保障和推动征信行业发展方面稍显不足。
三是对于个人信息保护不够明确,容易导致出现不当采集信用信息、滥用数据、侵犯合法权益的现象。因此,在立法层面尽快推进,明确数据采集和使用的原则及边界,对于征信行业健康发展至关重要。
总之,中国征信行业前路漫漫、道阻且艰,市场对于信用的需求非常强烈,未来若能解决具体政策落地、数据获取等瓶颈,打破数据共享、个人征信牌照发放等僵局,相信征信行业将会迎来爆发式增长。
爱分析是一家专注于创新企业研究和评价的互联网投研平台。转载请联系公众号:爱分析(ifenxicom)获得授权。

 02:52
02:52








 01:18
01:18
 10:27
10:27
 07:22
07:22
 09:49
09:49
 02:54
02:54
 05:30
05:30
 02:47
02:47
 09:28
09:28
 03:16
03:16


