
2020-05-14 14:00
AI不是人,为什么也会有性别偏见

扫码打开虎嗅APP

本文来自微信公众号:全媒派(ID:quanmeipai),原标题:《谷歌翻译困境破局:AI不是人,为什么也会有性别偏见?》,题图来自:IC photo
这些年来,Google Translate(谷歌翻译服务)一直被人诟病存在性别偏见现象,例如Google Translate会默认将某些“中性”职业和特定的性别联系起来,“医生”一定是男性,而“护士”则往往是女性。
从2018年开始,Google就尝试解决土耳其语和英语互相翻译时的性别偏见问题,为与性别有关的词条提供两种版本的翻译(和汉语不同,土耳其语是“中性”语言。汉语中有“他”和“她”两种人称代词来区分性别,而土耳其语种仅存在“o”一种人称代词,不区分性别),分别展示指代男性和女性对应的语境。但此种解决方案可扩展性和准确度都较低,在推广到其它语言的翻译时困难重重。

巴别塔——圣经传说中人类合力建造的通天塔。上帝为阻止此计划,让人类开始使用不同语言,无法沟通。以Google Translate为代表的AI机器翻译,被认为是有可能“重建巴别塔”的未来科技。图片来源:Hacker Noon
今年4月22日,Google AI Blog(Google AI业务新闻博客)发表了最新的文章,宣布Google Translate使用了优化升级的AI技术,进一步减少了翻译中出现的性别偏见现象,且拓展性较原方案更强,目前已经可以支持英语与西班牙语、芬兰语、匈牙利语以及波斯语的翻译场景。
为何“没有感情”的机器翻译模型也会自带性别偏见属性?Google Translate究竟使用了何种AI技术来改善文本中的性别偏见现象?本期全媒派编译VentureBeat文章,带你通过Google Translate在解决性别偏见方面的努力,了解AI行业探索“性别平等”之路。
不只是一个没有感情的机器

AI技术没有性别,却为何有性别偏见?图片来源:Medium
AI或机器学习技术自然没有性别可谈,可性别偏见和其它社会偏见(如对年龄、职业、宗教、种族、甚至是地域的偏见和歧视)却常出现在AI产品之中,这也是目前AI行业极为关注的问题之一。
Google Translate的负责人Macduff Hughes在接受采访时解释了AI技术“自带”偏见的原因,AI和机器学习技术是通过训练数据来实现对产品和服务的支持的,而这些训练数据都是来自真实的社会场景,也就难免带有社会中既有的各种偏见或歧视,接受了这些数据的AI模型则会“继承”这些观念。
用户在使用产品时又会受到这些偏见的影响,长此以往形成恶性循环,导致以性别偏见为代表的种种社会歧视越来越根深蒂固,而此种“偏见”的文本数据越多,AI模型会变得越来越“社会化”,和人一样对事物产生固有的认知偏见。
除去产生“性别偏见”的翻译文本外,Google Translate还曾因将胡乱输入的原文本翻译成恐怖的宗教预言而备受关注,这与Macduff Hughes解释的AI及机器学习的底层运作机制有直接的关系,因为Google Translate用来打造AI产品时使用的训练数据往往都是宗教文本。

Google Translate会将原本毫无意义的语言翻译成恐怖的末日预言。图片来源:Vice
在2018年,很多使用Google Translate的用户发现了一个可怖的现象。Google Translate会将本来毫无意义胡乱输入的原语言,翻译成末日预言,种种阴谋论也一时间甚嚣尘上。
对于当时热议的“阴谋论”事件,Macduff Hughes也做了相应的解释,这还是同Google的训练数据有关的。虽然有很多人把这件事归咎于神秘的宗教主义或者外星人攻击等原因上,但其实这是机器学习模型十分常见的问题。当用户的输入超出了机器学习模型的预期后,返回的数据也将是不合常规的。

2018年,Google Translate的用户发现在从毛利语至英语方向,翻译19个“dog”时,会显示出圣经中的末世预言。图片来源:Vice
BBN科技公司研究机器翻译的专家Sean Colbath,在当时曾对此事件发表同样的看法,“如果他们(Google Translate)使用宗教文本作为训练数据来构建机器学习模型,那最后产出的文本就很有可能是带有宗教意味的”。
在此次事件后,Google Translate也加大了对于AI去偏见化的力度,首先就是在男女性别平等方面的努力。正如Macduff Hughes所说的,“Google作为业内的先行者,会带领整个行业解决这些问题,首先就要解决在文本翻译服务中出现的性别歧视的问题”。
如果现实的语言文本中就存在性别偏见,那么翻译模型就会学习到这些偏见,甚至强化它们。例如,当一种职业在60%~70%的情况下都是由男性承担的,那么翻译系统就会学习到这一特征,而在产出翻译时,把这种职业100%地归属于男性,这一点就是Google Translate需要解决的问题。
有关这一问题最典型的例子就是“医生”和“护士”,在最早的Google Translate中,机器翻译都会将原本应是性别中性的词语转换成男性属性的词语,重现现实社会中已有的偏见,时任Google Translate产品经理的James Kuczmarski在博客中写到,“像‘强壮’、‘医生’等词语都会和男性挂钩,而‘护士’、‘美丽’等词语则会和女性挂钩”。
而使用Google Translate的很多用户常常都抱有学习语言的目的,这些用户需要知道不同场景中语言文本的细微差别。这也是Google Translate决定启动“性别项目”的初衷。
性别特定的翻译功能:Google Translate解决偏见初尝试
其实早在2016年,Google Translate作为机器翻译行业技术探索的先行者就一直在应用最新的技术。2016年,Google Translate首次使用了“神经机器翻译”(Neural Machine Translation),而摒弃了经典的“统计机器翻译”(Statistical Machine Translation)。“统计机器翻译”其实是对文本进行逐字翻译,但是无法考虑到词性、时态、语序等语法因素,常导致最后的译文错误百出。而“神经机器翻译”则是逐句翻译,会将上述因素进行更好的处理。
使用了“神经机器翻译”技术的Google Translate可以产出更加自然、顺畅的译文,也具备了产出不同风格文本的潜力(如正式场合使用的语言风格或者生活中使用的俗语俚语风格)。
到了2018年12月,Google Translate为了解决性别偏见问题,又推出了“性别特定的翻译功能”(Gender-specific Translation)。土耳其语作为一种中性语言(即没有区分性别的人称代词)首先开始支持该功能。
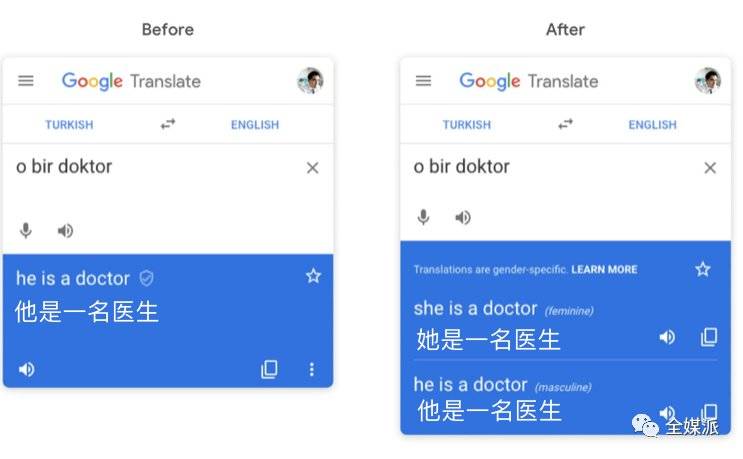
“性别特定的翻译功能”支持译出两种性别场景的译文,供用户选择。图片来源:The Verge
在此新功能的支持下,用户输入一条无明显性别信息的原文,会被转换为“男性”和“女性”两种场景的翻译。两种翻译都会展示在翻译结果中,由用户自行选择。
Google Translate研发团队采用了特殊的处理模型,通过三个步骤将原文本转换为两种性别格式的翻译文本。首先,机器模型需要判断原文是否为“中性”语言文本,即未明确指出人称性别的文本;然后,Google Translate将产出男女两种人称的独立译文;最后再进行准确度检查。
此种处理模式首先被应用在将土耳其语翻译为英语的场景中,可支持短语和短句的翻译。随后又被拓展到将英语翻译为西班牙语的场景中,西班牙语和土耳其语与英语的互译是Google Translate中用户需求最大的两种语言对。这一功能最早支持用户在Chrome或者Firefox浏览器上使用,后续又计划在移动端及其它平台推出。

Google一直在拓展Google Translate的使用平台,其中也包括自家的蓝牙耳机Pixel Buds。图片来源:The Verge
但是当Google Translate准备将这一模式应用在更多语言的翻译中时,发现此方案的可扩展性有很大问题。具体来说,在使用“神经机器翻译”技术产出两种“性别”的文本时,整个机器翻译系统的查全率较低。比如,当出现10条需要进行“性别特定翻译功能”处理的文本时,系统只能够辨认其中的4条。此外,如果要为每一种像土耳其语一样的“中性语言”配置可进行性别判定的分类识别器,将需要庞大的数据量来训练机器模型,可拓展性极低,短期之内无法将此种功能应用到更多语言上。
优化翻译模型,进一步减少性别偏见
今年的4月22日,Google Translate宣布解决了原先方案可拓展性较低的问题,并将“性别特定翻译功能”拓展到英语与西班牙语、芬兰语、匈牙利语以及波斯语的翻译场景中。这种拓展性更强的解决方案优化了原先的处理模型,采用“重写”(Rewriting)加“译后编辑”(Post-editing)的方法,取代了原先的“判断”加“分别翻译”的处理模式,不再依赖于需要大量数据进行训练的性别识别器。
“我们此次的AI技术方案实现了显著的性能提升,不仅提高了性别判定的质量,而且将功能拓展到了另外4种语言上。”Google高级软件研发工程师Melvin Johnson这样写到,“我们将继续沿着这个方向探索下去,下一步准备解决长文本翻译中的性别偏见问题。”
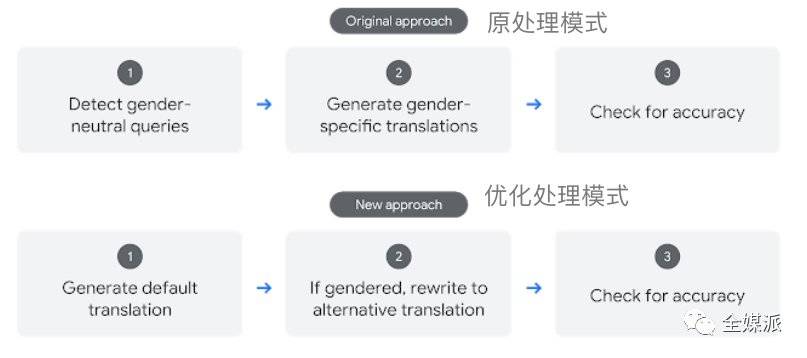
原有处理模式和优化处理模式对比。图片来源:Google AI Blog
在新的处理模式下,系统不需要在第一步对原文进行判别,而是直接产出默认的翻译文本;在第二步则由“重写”功能,产出与默认翻译文本对立性别的本文。比如说,默认翻译文本是“他是一名医生”,则重写功能会产出对应的文本“她是一名医生”。最后再对两则翻译文本进行准确度检查,保证只有性别因素不同,其它因素保持一致。
要实现优化模式中的“重写”功能也绝非易事,Google为了实现该功能使用了百万级的训练语例,这些训练文本中包含了区分两种性别的双语词组。由于这样规模的双语文本数据在短期之内很难获得,Google Translate团队还利用算法对现有的单语数据进行了处理,为其生成了包含对应性别的语例文本。

用算法对单语文本进行处理,产出对应的双语文本数据。图片来源:Google AI Blog
获得足够的训练数据后,Google Translate也加入了标点和格的变化(指主格、宾格、所有格等变化),增强模型的稳定性。利用此种模型可实现高达99%的性别判定准确度。
Google Translate此次使用的优化版AI技术,将4种语言与英语的文本互译中的“性别偏见”减少了90%以上,而用使用原方案的土耳其语—英语翻译场景中,对“性别偏见”的解决度也从60%上升到了95%。系统判别是否需要展示两种性别文本的准确度稳定在97%。

Google Translate在利用AI进行机器翻译的道路上引领着技术风潮。图片来源:Pixabay
Google Translate虽然称不上完美,也远远无法代替专业的人类译者,但其在减少性别偏见的道路上的每一次进步,都体现了Google对于减少AI性别偏见的努力。AI技术是由人类创造的并塑造的,技术从业者需要像Google Translate一样,打造更公正平等的AI产品反哺社会,帮助人类向更文明的方向发展。
参考链接:
1. https://venturebeat.com/2020/04/22/google-debuts-ai-in-google-translate-that-addresses-gender-bias/
2. https://ai.googleblog.com/2020/04/a-scalable-approach-to-reducing-gender.html
3. https://techcrunch.com/2018/12/07/google-translate-gets-rid-of-some-gender-biases/
4. https://www.theverge.com/2019/1/30/18195909/google-translate-ai-machine-learning-bias-religion-macduff-hughes-interview
5. https://en.wikipedia.org/wiki/Turkish_grammar#Pronouns
6. https://www.vice.com/en_us/article/j5npeg/why-is-google-translate-spitting-out-sinister-religious-prophecies
7. https://thenextweb.com/neural/2020/04/23/google-introduces-improved-ai-to-address-gender-bias-in-translate/
本文来自微信公众号:全媒派(ID:quanmeipai)

 11:59
11:59









 05:05
05:05
 07:46
07:46
 13:10
13:10
 08:45
08:45
 20:24
20:24
 05:47
05:47
 31:30
31:30
 06:16
06:16
 09:57
09:57


